[review] GoogLeNet (2014)
Going deeper with convolutions 논문을 Review 해보려고 한다.
Abstract
Inception이라는 codename의 deep convolution neural network는 classficiation과 detection 모델로서 제안되었다.
주 특징은 네트워크 내부의 computing reosource들을 향상된 방식으로 활용하는 것으로, computational budget을 변화시키지 않으면서 깊이와 너비를 확장시키는 방법으로 달성되었다.
Architecture는 Hebbian Principle과 multi-scale processing의 아이디어가 적용되었다.
Hebbian Principle?
- 뉴런 간의 연결 강도가 동시에 활성화되는 경우 강화된다는 학습 원칙으로, '함께 활성화되는 뉴런은 함 연결된다'는 아이디어를 기반으로 한 원칙
Multi-scale Processing?
- 다른 크기 또는 해상도의 정보를 동시에 처리하는 방법으로, 이미지나 신호의 다양한 세부 정보를 파악하고 이해하기 위한 처리 방법
Introduction
Convolution network의 등장으로 이미지 인식과 객체인식 분야는 급격한 발전을 이루었고, 새로운 아이디어와 알고리즘, 네트워크 architecture의 발전을 기초로 크게 성장이 가능했다.
본 논문은 computer vision을 위한 효율적인 DNN architecture를 소개하기 위한 것으로 'Inception Module'을 기반으로 'deep'한 network architecture를 소개한다.
새로운 convolution 기반의 Deep Neural Network Architecture로서 Inception module을 기반으로 한 computer vision의 classficiation과 object detection을 위한 모델로,
computation expenses는 최소화하면서 network의 depth을 깊게 하여 모델의 성능을 끌어올린 architecture를 소개하는 논문이므로,
1) inception module이 무엇인지, (multi-scale processing)
2) computational costs가 증가하지 않는 이유는 무엇인지, (hebbian principle)
에 대해 중점적으로 파악하면 좋을 것 같다는 생각이 든다.
Related Work
조금 더 나중에,, 파악해보자,,
Motivation and High Level Considerations
DNN의 성능을 향상시키기 위해 가장 빠른 방법은 'Size'를 키우는 것으로, 모델의 depth와 width를 모두 확장시키는 것이다. 하지만 DNN의 Size를 키웠을 때 발생하는 주요 문제는,
1) 많은 parameters로 인한 overfitting의 문제와,
2) computer resources의 막대한 사용으로 인한 cost 문제가 있다.
이 두 문제를 해결하기 위해서는 Fully connected 뿐만 아니라 convolution 내에서도 Sparsely connected architecture를 사용하는 방법이 있다. 하지만 현재의 computing infra가 non-uniform sparse data structure에 대한 계산에 있어 비효율적이라는 점에서 Sparse Connect를 전적으로 적용하는 것은 사실상 불가능하다.
Sparsely Connect?
- 'Sparse Neural Network'는 네트워크 내의 연결이 일부 뉴런 간에만 형성되는 신경망 구조로, 연결이 적어 전체적인 계산 비용을 절약하는 동시에 모델이 주요한 특징에만 집중하여 중요한 특징에 대한 학습을 강조함과 동시에, 불필요한 연산 감소로 인한 빠른 학습과 추론이 가능하다는 장점을 가진 네트워크 모델이다.
- 네트워크의 연결성을 낮추고 계산 효율성을 향상시킬 수 있다는 점에서, 뉴런 간의 연결을 조절하여 학습의 효율성을 증가시킬 수 있다는 Hebbian learning의 principle의 idea와 일맥상통
Sparse Data structure의 구조적인 한계와 오늘날 computing 환경에서 sparse connection의 이점을 중점적으로 사용하여 위 두 문제점을 해결하기 위해서는 여전히 추가적인 기술적인 도전이 필요한 상태이기 때문에, 다른 방법을 적용할 필요가 있다. (Convolution Network 역시 초기에는 random하고 sparse한 connection table을 사용하였지만 gpu computing resource를 적극 활용하기 위해 fully connected 방식으로 회귀)
Inception module의 architecture는 sparse network의 장점을 dense matrix에서 사용될 수 있는 여지를 파악하기 위한 시도에서 등장한 것으로, sparse connection 을 통해 계산 효율성을 높이기 위한 시도에서 등장하였다. 모델 평가 결과는 성공적이었으나, 이러한 성공과 효율성이 architecture의 construction에서 기인한 것인지에 대해서는 의문이 남아있어 추가 연구와 평가는 필요하다.
Inception Module과 architecture는 sparse connection을 통한 계산 효율성 증가의 장점을 Dense matrix를 활용하여 구현하고, 이를 통해 계산 효율성과 model의 depth 증가를 통한 성능 향상을 추구하기 위한 시도에서 등장하였으나, 본 모델의 성공 여부가 architecture의 construction 특성에 기인한 것인지에 대해서는 여전한 의문을 갖고 있다.
Architectural Details
Inception Architecture의 주요 아이디어는 다음과 같다.
"Convolution Network"에서 최적의 local sparse structure를 어떻게 근사적으로 구조화하고,
이를 (현대의 computing envirionment에서) 사용가능한 Dense component로 cover(형성)할 수 있을 것인가?"
이에 대한 해답을 찾기 위해서는 optimal local sparse construction을 찾고 이를 공간적으로 반복해야 한다. (이 때 optimal local sparse construction == Inception module)
본 논문은 Arora의 논문에서 제안된 방법을 차용하여, 이전 layer의 unit들이 input image의 정보를 담고 있고, 이 unit들이 filter bank로 그룹화됨을 가정한다. 즉 다음 layer의 구성에 있어 이전 layer의 정보를 담고 있는 feature map의 집합으로서 filter bank를 구성하여 활용한다는 것이고, 이를 단일 벡터로 concatenate 하여 다음 layer의 input data로 전달한다.
Arora's Suggestion?
- layer by layer construction을 제안하는데, 이전 layer의 상관 통계 분석을 토대로 높은 상호 관련성을 갖는 units을 하나의 그룹으로 클러스터링 하여, 다음 layer의 unit으로 구성하고, 이를 이전 layer의 unit과 연결하는 것이다.
- 이를 통해 layers들은 서로 연결되며, early layer의 상호 관련성이 높은 units들이 다음 layer에 전달되어, 해당 관련성이 layer를 통해 계승되는 효과가 생긴다. (Hebbian Principle과 Sparse Connection 관련)
이 때 filter bank로서 feature map의 사이즈는 (1 * 1), (3 * 3), (5 * 5)로 제시되는데, 이는 어떤 필요에 의해 정의되기 보다는 편리성을 위해 정해지게 되었다.
- 초기 수준의 layer에서 각 correlated units은 특정 지역적 위치에 집중되어 있다는 점에서, 정보 손실을 최소화하기 위해 (1 * 1) 사이즈의 feature map을 사용하지만, patch-alignment issue로 인해 (3 *3), (5 * 5) feature map 편의상 사용하는 것이다.
Patch-Alignment Issue?
- Convolution 연산 과정에서 입력 이미지의 작은 부분을 patch라고 하는데, 이를 처리할 때 발생하는 패치들이 정확하게 맞물려야 하는 문제
- 차원 일치라고 생각하면 편할 것 같다.
결국, Inception Module은 이전 layer의 input을 3가지의 서로 다른 사이즈의 feature map으로 feature를 다양한 수준에서 추출하고, 이 filter bank를 단일 벡터로 concatenate하여 다음 layer의 input data로 전달한다. 서로 다른 사이즈의 feature map은 서로 다른 특징을 추출한다는 점에서 독립적이고, 추출한 특징을 다음 layer로 전달하고, 다음 layer에서 역시 같은 사이즈의 filter bank를 반복적으로 사용한다는 점에서 특정 feature를 반복적으로 추출하는 모듈이다.
- inception module의 반복적인 사용을 토대로, lower layer에서는 데이터의 높은 공간적 집중도로 인해 (1 * 1) feature map의 사용 비중이 상대적으로 높아야 할 것이고, ((1 * 1) feature map은 사실상 identity map과 동일하다는 점에서, inception module은 input data를 그 자체로 반영하기 위해 (1 * 1) feature map을 사용하기도 한다는 특징이 있다.)
- 마찬가지로 higher layer에서 추상화된 특징이 포착될 가능성이 높고, 이는 곧 데이터의 공간적인 집중도가 낮아짐을 의미하므로, 결과적으로 (3 * 3), (5 * 5) feature map의 사용 비중이 높아져야 한다.
- 즉, 다양한 feature를 추출할 수 있는 filter bank가 있는 inception module을 깊게 쌓음으로써, 다양한 수준에서 다양한 크기의 feature를 추출할 수 있는 장점이 생기는 것이다.
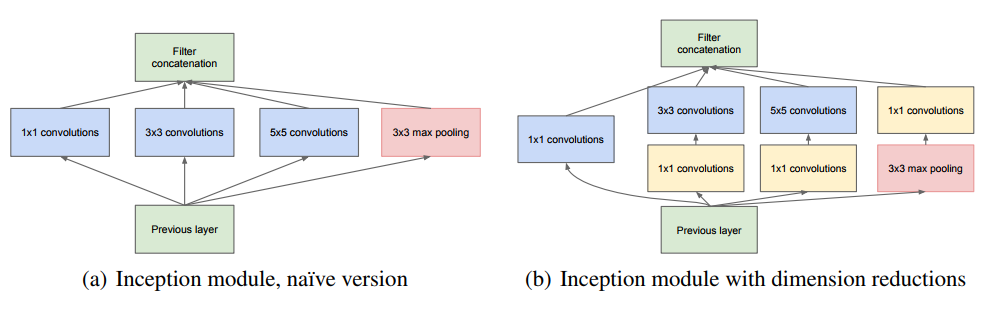
기본 architectural idea는 (a) 안이었으나, 두 가지 큰 문제점이 있어 차원 축소의 개념이 사용되는 (b) architecture가 고안되어 사용되었다.
- (5 * 5) feature map은 필터의 갯수가 많은 convolution layer에서 사용될 때 굉장히 높은 연산이 필요 (concatenate되어 전달된 input이 많은 filter bank로 인해 차원이 높아지게 되면, 계산량이 상당해지는 문제가 발생) → 차원 축소의 개념이 필요 (filter의 갯수를 조절)
- pooling layer를 더해주는 방식이 적용되는데, 그렇게 되면 stage to stage로 전달되는 값의 차원이 계속적으로 높아지는 문제가 발생 → 차원 축소의 개념이 필요 (filter의 갯수를 조절)
저차원의 embedding 역시 상대적으로 많은 정보를 포함할 수 있으나, embedding은 정보를 압축한 형태로 나타낸다는 점에서 모델링에 어려움이 있기 때문에, 축소가 필요한 구간(연산량이 많이 소요되는 (3 * 3), (5 * 5) feature map)에만 적용한다. 활성함수로는 ReLu를 사용한다.
Inception Module에서 활성함수로 ReLu를 사용하는 이유?
- Sparsity를 살릴 수 있다는 장점이 있어 계산 효율적 : 입력이 음수인 경우에는 0을 출력하기 때문에, 해당 neural이 죽는 효과가 있어 역전파 과정에서 연산이 줄어드는 효과가 생긴다.
- Gradient Vanishing 문제 감소 : sigmoid와 tanh과는 달리 입력이 양수인 경우에는 입력값을 그대로 출력한다는 점에서 gradient가 소실되는 문제가 전혀 발생하지 않는다.
일반적으로 Inception Network는 Inception Module이 반복적으로 쌓인 구조로 이루어져 있으며, 간헐적으로 stride=2인 MaxPooling Layer가 Resolution을 줄이기 위해 사용되는 구조이다. 논문에서는 구조의 비효율성을 줄이기 위해 lower layer에서는 일반적인 CNN을 사용하고, high layer에서 Inception Module을 사용한다고 밝혔다.
Inception Architecture의 장점은 크게 두 가지이다.
- 전체적인 계산 복잡도가 통제되는 한에서, 각 inception module에서 차원의 수를 조절할 수 있다.
- 각 module에서 다양한 사이즈의 feature map을 사용하기 때문에 다양한 scale을 반복적으로 추출할 수 있다.
Inception Model은 Inception module의 반복적인 사용과 일반적인 CNN이 결합된 모델이다.
Sparse Connection 개념을 차용하여 parameter의 급격한 증가를 제한하여 연산 효율성을 극대화하고,
다양한 feature map을 사용하고, 연산의 결과 값을 concatenate하여 다음 module의 input값으로 사용한다는 점에서, 다양한 특징을 다층의 layer에서 반복적으로 추출할 수 있다는 장점이 있다.
이는 Sparse Network와 Hebbian Principle, Multi-scale processing의 아이디어를 차용한 것이다.