-
데이터 변환_스케일링machine learning 2024. 2. 25. 16:17
데이터 스케일링(data scaling)은 데이터 전처리 과정의 핵심 단계 중 하나로, dataset의 features를 특정 범위로 조정하거나, 데이터의 분포를 표준화하는 과정으로, 주요 목적은 다음과 같다.
1. 특성 간의 균형 조정 (★★★)
데이터 feature를 특정 범위 값으로 조절하여 feature 크기에 따른 불균형을 조정할 수 있다. 이를 통해 특성의 중요도를 공정하게 해석하여 overfitting을 극복할 수 있다.
이는 특히 거리 기반의 알고리즘(KNN, K-Means Clustering 등)에 있어 특성 간 거리 측정이 더 공정하게 이루어지도록 하여 알고리즘의 정확도와 성능을 향상시킨다.
2. 모델의 수렴 속도 향상
scale을 일치시킴으로서 최적화 알고리즘이 수렴하는 속도를 일정하게 조절하여 최적점을 찾는데 상대적인 시간을 축소시킬 수 있다.
3. 수치적 안정성 향상
모든 feature의 수치를 특정 범위로 한정하여 표현함에 따라 수치적 불안정성으로 인한 알고리즘의 안정성 저하 문제를 극복 가능
data scaling과 관련하여 혼동되는 용어(standardizing, normalizing)가 있는데,
1. Scaling
- 데이터의 비율을 그대로 유지하는 상태에서 범위만 바꾼다는 의미로
- default로 데이터의 범위를 [0, 1] 사이로 조정해주지만, feature_range 설정을 통해 기타 값으로의 범위 변경이 가능하다.
- sklearn의 MinMaxSCaler
2. Standardizing
- 평균을 기준으로 계산된 분포의 표준편차가 1이 되도록 feature의 값들을 변형시키는 것으로,
- 데이터를 정규분포(평균 = 0, 표준편차 = 1)에 가까운 형태로 변형시는 것으로, 이를 위해 scaling을 같이 적용할 수 있다.
- sklearn의 StandardScaler, RobustScaler
3. Normalizing
- scaling과 standardization과 의미가 유사하다는 점에서, 사용 전에 그 용어의 정의가 필요
- 일반적으로 data preprocessing 단계에서는 scaling과 standardization의 용어를 사용하고, batchnormalization과 같은 전체 데이터의 재분포를 통한 normalize를 위해 사용한다는 측면에서는 normalization의 용어가 적절해보이나, 헷갈리는 것이 사실이다.
- sklearn의 Normalizer
4. Regularization
- 모델의 복잡성을 제어하여 과적합을 방지하고 모델의 일반화 성능을 향상시키는 방법
- L1 정규화(Lasso - 가중치의 절대값 합을 제한), L2 정규화(Ridge - 가중치의 제곱 합을 제한) 사용
- 특정 Parameter가 지나치게 커져 Overfitting이 발생하지 않도록 하는 역할 - 가중치에 대한 추가적인 제약을 부여
- 딥러닝 용어 정리, L1 Regularization, L2 Regularization 의 이해, 용도와 차이 설명 (tistory.com)
데이터 스케일링 방법은 크게 4가지가 있다.
from sklearn.preprocessing import MinMaxScaler, StandardScaler, RobustScaler, Normalizer데이터 스케일링 전에, 어떤 scaling method을 사용할 것인지 결정하기 위해서는, 우선적으로 원본 데이터의 확률분포와 이상치 데이터를 확인하는 것이 좋다. 'kdeplot'은 주어진 데이터의 확률분포를 추정하고 시각화하는 함수이다.
import seaborn as sns import matplotlib.pyplot as plt # kdeplot으로 KDE 플롯 생성 sns.kdeplot(data, shade=True, color="blue", linewidth=2.5) plt.show()1. MinMaxScaler (Scaling)

MinMaxScaler - 본래 데이터의 분포를 유지한다는 점에서, 본래 데이터의 정보를 변형시키지 않는다.
- 최소값과 최대값이 이상치에 의해 크게 영향을 받을 수 있다는 점에서, 이상치가 아닌 다른 data point들이 좁은 범위에 압축될 수 있다. (이상치 데이터가 데이터 분포에 영향을 미칠 수 있음)
- 데이터 본래의 정규분포를 변형시키지 않고, 이상치의 영향을 그래도 확인하기 위해 사용
- scaling을 위해 가장 먼저 시도해볼 수 있는 가장 일반적인 방법
2. RobustScaler (Standardizing)
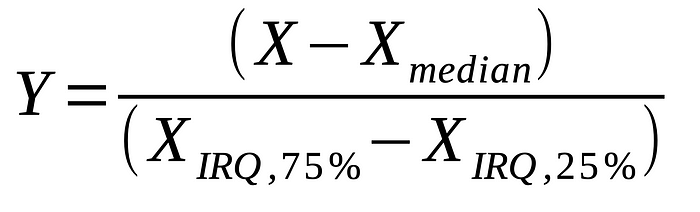
RobustScaler - 데이터의 중앙값과 사분위수 범위(IQR : Interquartile Range)를 사용하여 scaling하는 방식
- 데이터의 중앙값가 IQR을 사용한다는 점에서 이상치의 영향을 크게 받지 않는다.
- 중앙값과 IQR을 사용한다는 점에서 데이터의 원본 분포를 완전히 보존하지 않으며, 이는 결국 feature 값을 변형시킨다는 점에서 standardizing에 해당
- 데이터의 원본 분포를 보존하지 않고 IQR과 중앙값에 의해 scale이 조정된다는 점에서 변환된 데이터의 최종 범위를 미리 예측하기가 어렵다.
- 이상치가 많은 데이터셋에서 활용하기에 유용한 방법
3. StandardScaler (Standardizing)
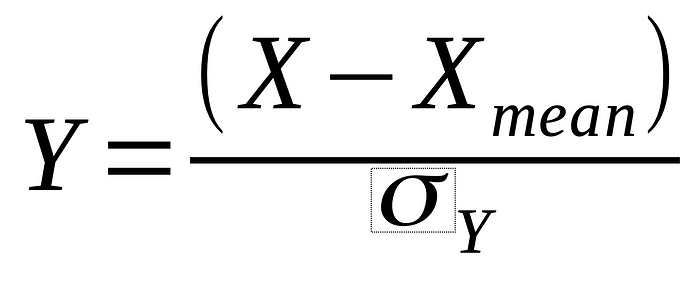
StandardScaler - 각 feature의 평균을 0, 분산을 1로 조정하여 데이터를 표준화하는 방법으로 standardizing에 가까운 기법
- 미리 정의된 간격과 범위 내에서 데이처 변형이 이루어지는 것이 아니며,
- 평균과 표준편차에 의해 분포가 영향을 받는다는 점에서 MinMaxSclaer와 마찬가지로 이상치의 영향으로부터 자유롭지 못하다.
- 데이터가 대략적으로 정규분포를 따를 때 가장 잘 작동한다는 점에서, 데이터가 비대칭적인 경우에는 이상치의 영향을 많이 받는다.
<< MinMaxSclaer와 StandardScaler의 비교 >>
- MinMaxScaler는 원본 데이터의 분포를 유지한다는 점에서 데이터 변형이 없다. 반면, StandardScaler는 평균이 0, 분산이 1인 표준편차의 분포로 데이터 분포를 변형시킨다는 점에서 데이터 변형이 있다.
- MinMaxScaler는 이상치가 최소값 혹은 최대값으로 선택될 경우 다른 데이터 포인트들이 좁은 범위 내로 압축된다는 점에서 상대적인 단점이 있다. 반면, StandardScaler는 평균과 표준편차를 사용하여 데이터 분포를 축소 및 변형시킨다는 점에서, 이상치가 전체 데이터셋의 스케일에 미치는 영향을 분산시킬 수 있어 이상치가 있더라도 다른 데이터 포인트들 사이의 상대적인 관계를 유지한다는 상대적인 장점이 있다.4. Normalizer (Normalizing)

Normalizer - feature의 column값이 아닌 row 값에 적용되는 기법으로,
- 개별 행의 feature vector를 해당 벡터의 norm으로 나누어 특정한 길이를 갖도록 만드는 기법
- 각 행을 독립적으로 처리하며, 각 행의 모든 feature data들을 해당 행의 norm 으로 나누어 정규화
- 이 방식은 각 행의 특성 간 상대적 거리 비율은 유지하면서 모든 특성 데이터를 동일한 스케일로 조정하는 것으로, 각 행 간의 크기 차이를 제거하여 각 행에서 feature의 방향성이나 패턴 분석을 위해 적용하는 기법
- 즉 특정 데이터 포인트 별로, 데이터 포인트의 특성을 구성하는 feature의 상대적 거리를 표현하여, 특정 데이터의 특성을 나타내는데 영향을 미치는 feature의 방향성과 거리를 측정하기 위한 목적에서 사용되는 normalize 기법
참고 링크
Scale, Standardize or Normalize with sklearn - Google Sheets
Scale, Standardize or Normalize with sklearn
Sheet1 Preprocessing Type,Scikit-learn Function,Range,Mean,Distribution Characteristics,When Use,Definition,Notes Scale,MinMaxScaler,0 to 1 default, can override,varies,Bounded,When want a light touch.,Add or substract a constant. Then multiply or divide b
docs.google.com
'machine learning' 카테고리의 다른 글
가상 데이터의 활용 (0) 2024.02.25 데이터 축소 (0) 2024.02.25 데이터 변환_인코딩 (0) 2024.02.25 데이터 정제 (0) 2024.02.25 데이터 전처리 과정 (0) 2024.02.25