-
가상 데이터의 활용machine learning 2024. 2. 25. 16:32
가상 데이터를 생성하는 이유
- 테스트 이전에 모델의 정상 작동 여부를 확인하기 위함
- 알고리즘의 특성을 이해하거나 성능의 평가를 위함
1. make_blob을 사용한 가상 데이터 생성
make_blob을 통해 생성되는 데이터는 정규 분포를 따르는 가상의 데이터로,
여러 개의 클러스터가 존재하는 형태로 데이터가 생성되어, 다중 분류를 위한 클러스터 데이터 생성이 가능
from sklearn.datasets import make_blobs x, y = make_blobs(n_samples=100, centers=3, n_features=2, random_state=1234) print(x.shape, y.shape) # n_samples : 생성할 데이터 샘플의 수 # centers : 생성할 클러스터의 수 # n_features : 각 샘플의 feature 갯수 # x : data, y : label# make_blob을 통해 생성한 데이터를 dataframe화 import pandas as pd import numpy as np blob_data = pd.DataFrame(dict(x_1 = x[:, 0], x_2 = x[:, 1], label = y)) # feature 이름을 x_1, x_2라고 가정 # blob_data의 시각화 plt.scatter(x=blob_data['x_1'], y=blob_data['x_2'], s = 100, c = y) # s : datapointer의 크기 # c : pointer의 색으로, 색이 아닌 label이 주어진 경우, label의 갯수만큼 다른 색 배정 plt.xlabel('X_1') plt.ylabel('X_2') plt.show()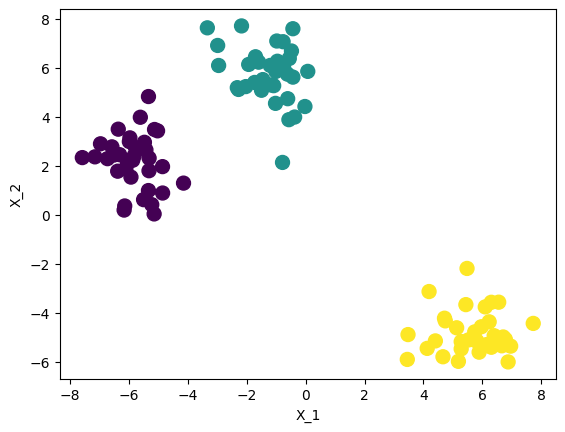
blob_data의 분포 - 3개의 cluster 2. make_moon을 활용한 가상 데이터 생성
make_moon을 통해 생성되는 가상 데이터는 초승달 모양의 클러스터 2개를 생성하여 이진 분류 문제를 평가하기 위한 가상 데이터셋을 제공한다.
make_moon을 통해 생성된 데이터는 비선형적인 결정 경계를 갖고 있다는 점에서 비선형 분류 모델을 평가하기 위해 사용되며, 비선형 분류 모델이 비선형적 특성을 얼마나 잘 학습하는지 여부를 평가할 수 있다.
# make_moon : 초승달 모양 from sklearn.datasets import make_moons x, y = make_moons(n_samples=500, noise=0.05, random_state=1234) # noise : Gaussian 분포의 표준편차# make_moon을 통해 생성한 데이터의 dataframe화 moon_data = pd.DataFrame(dict(x_1 = x[:, 0], x_2 = x[:, 1], label = y)) # moon_data의 시각화 plt.scatter(x=moon_data.x_1, y=moon_data.x_2, s = 50, c = y) plt.xlabel('x_1') plt.ylabel('x_2') plt.show()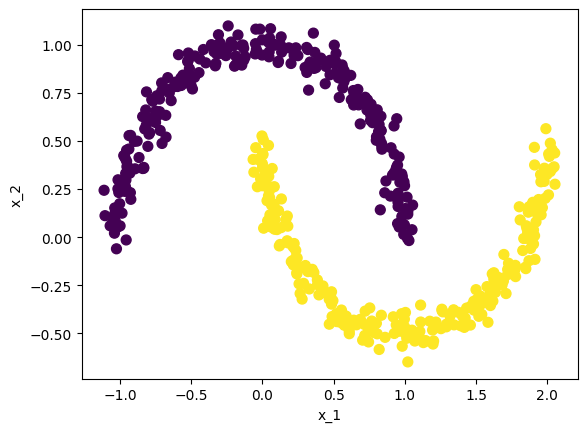
moon_data의 분포 - 2개의 초승달 cluster 3. make_circles를 활용한 가상 데이터 생성
make_circles를 통해 생성되는 가상 데이터는 원 모양의 2개의 클러스터를 생성하여 이진 분류 문제를 위한 가상 데이터셋을 제공한다.
make_moons와 마찬가지로 데이터셋이 비선형적인 결정 경계를 가진다는 점에서 비선형 분류 모델을 평가하기 위한 목적으로 사용되며, 비선형적 특성을 얼마나 잘 학습하는지 평가한다.
from sklearn.datasets import make_circles x, y = make_circles(n_samples=500, noise=0.05, random_state=1234)# make_circles를 통해 생성한 데이터의 dataframe화 circle_data = pd.DataFrame(dict(x_1 = x[:, 0], x_2 = x[:, 1], label = y)) # circle_data의 시각화 plt.scatter(x=circle_data.x_1, y=circle_data.x_2, s=50, c=y) plt.xlabel('x_1') plt.ylabel('x_2') plt.show()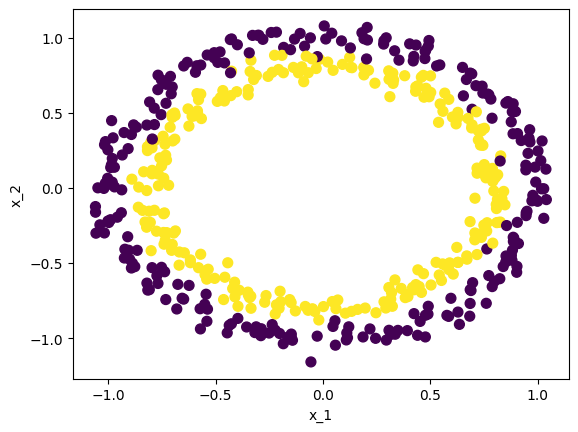
circle_data의 cluster - 2개의 circle 4. make_regression을 활용한 가상 데이터 생성
make_regression을 통해 생성되는 가상 데이터는 선형 데이터를 생성한다는 점에서, linear regression에 있어 얼마나 regression을 잘 하는지를 평가하기 위한 목적으로 사용이 가능하다.
from sklearn.datasets import make_regression x, y = make_regression(n_samples=500, n_features=1, n_targets=1, noise=15, random_state=1234)# make_regression을 통해 생성한 데이터의 dataframe화 regression_data = pd.DataFrame(dict(x = x[:, 0], label = y)) # regression_data의 시각화 plt.scatter(x=regression_data.x, y=regression_data.label, s=50, c=y) plt.xlabel('x') plt.ylabel('y') plt.show()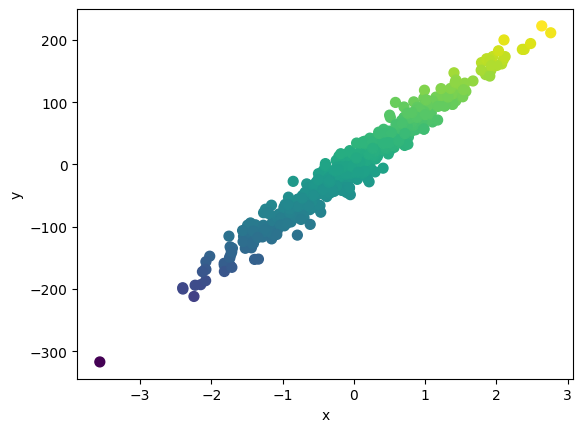
regression_data의 cluster 'machine learning' 카테고리의 다른 글
train _vs_ valid _vs_ test (0) 2024.03.15 classification _vs_ regression (1) 2024.03.15 데이터 축소 (0) 2024.02.25 데이터 변환_인코딩 (0) 2024.02.25 데이터 변환_스케일링 (0) 2024.02.25