-
[review] YOLOV1 (2015)deep learning/paper review 2024. 2. 19. 12:09
You Only Look Once : Unified, Real-Time Object Detection
논문 링크 : [1506.02640] You Only Look Once: Unified, Real-Time Object Detection (arxiv.org)
Abstract
YOLOv1은 object detection을 regression의 관점에서 접근한다. (bounding box의 존재, class probability)
(이전의 object detection 연구는 classifier가 detection을 수행하는 방식으로 작업)
단일 신경망 구조를 갖고 있으며, 전체 데이터에 대한 한번의 연산을 통해 bounding box와 class probabilities를 predict하는 모델로, end-to-end로 detection performance를 수행한다.
YOLO는 굉장히 빠르고, object의 general representation을 빠르게 학습한다는 점에서 성능이 뛰어나다.
Introduction
YOLO 모델은 객체를 인식하는 인간의 인지 과정을 모방한다. (Human glance at an image and instantly know what objects are in the imag,e where they are, and how they interest.)
You Only Look Once : 인간은 한 번 보고도 객체를 탐지할 수 있다!
당시 detection system은 classifer가 detection을 수행하는 방식으로 설계되었는데, classifier가 객체를 분류하고 해당 객체의 스케일과 위치를 평가하는 방식이었다. Sliding Window 기법을 사용하여 전체 이미지에 대해 classifier로 평가하는 방식으로 작동되었다.
* DPM (Deformable Part Model)
- 객체가 여러 부분으로 구성되어있고, 이러한 부분이 서로 어떻게 연결되는가에 관해 모델링하는 모델로, 객체의 구조적인 부분을 고려하여 객체를 인식하는 데 사용되는 방법으로,
- sliding window 기법을 활용하여, window에서 파악되는 부분을 통해 전체 객체를 파악할 수 있다.최근의 R-CNN 계열의 접근 방식의 경우 객체가 존재할 수 있는 bounding box를 생성하고, 해당 bounding box에 대해 classification을 수행하는 방식을 사용하고 있다. 이후 bounding box를 재정의하고, 중복되는 box들을 제거하고, box들의 예측 점수를 다시 계산하는 등의 post-processing 과정을 거친다. (Faster-RCNN 참고) 이러한 복잡한 구성은 느리고 최적화가 어렵다는 한계가 존재한다.
이와 달리, YOLO는 simple 한 architecture를 갖고 있다. 단일 convolutional network가 동시에 bounding boxes들을 예측하고, 해당 boxes에 대한 class probabilities를 예측한다.
- 따라서 detection이 굉장히 빠르다. 이에 더해 평균 정확도 역시 상대적으로 높다.
- Fast-RCNN에 비해 background error가 2배 이상 적다. 이는 DPM 모델에서 객체를 인식하는 방법을 사용하지 않고, 전체 이미지를 고려하여 객체를 탐지하는 데 사용하기 때문이다.
- YOLO 모델은 객체의 generalizable representation을 학습하기 때문에, 새로운 도메인에 대해 사용할 때 크게 문제가 생기지 않는다. (객체의 일반적인 특징을 학습하기 때문에, 새로운 도메인에 적용하더라도 예측 가능한 객체에 대한 예측이 크게 망가지지 않는다.)
- 반면 정확도 측면에서는 상대적으로 뒤쳐져 있는 것이 사실이며, 이는 빠르게 적절한 속도를 제공한다는 장점과 trade off 관계이다.
Unified Detection
YOLO는 Unified Detection Model이다.
YOLO는 각각의 bounding box를 예측하기 위해 전체 이미지로부터 얻은 features를 사용한다. 동시에 모든 bounding boxes의 class를 예측한다. 이는 YOLO 네트워크가 전체 이미지와 이미지 안의 전체 객체에 대해 전역적(globally)으로 판단한다는 것을 의미힌다.
[YOLO의 Object Detection 과정]
- Input Image를 S * S gird로 구분
- 만약 객체의 중심이 해당 grid cell에 있을 경우, 해당 grid cell은 객체를 detecting 하는 데 있어 resoponsible ( = 객체의 중심이 포함되어 있는 grid cell은 해당 객체에 대한 bounding box와 class를 예측하는데 있어 중요함)
- 각 grid cell에서 B개의 bounding box 예측
- 전체적으로 S * S * B 개의 bounding box가 예측됨
- 각 bounding box에 대한 confidence score와 객체가 있을 것이라고 판단되는 predicted bounding box의 (x, y, w, h) 좌표 값을 예측
- confidence score : 해당 bounding box에 대한 신뢰도를 측정하는 지표로, 객체가 존재하는지 여부와 해당 bounding box가 GroundTruth box와 얼마나 일치하는지에 관한 신뢰도 점수
\(P_r(Object) * IOU_{truthpred})
-
- (x, y, w, h) : 예측한 bounding box의 해당 grid cell 내에서의 상대 중심 좌표와 상대 w h 비율
- 중심 좌표를 사용하는 이유
- grid cell 내에서의 예상되는 객체의 위치를 상대적으료 표현할 수 있고,
- 따라서 여러 객체를 동시에 감지할 수 있으며,
- 상대적 크기 표현이 간단하기 때문에 경제적이기 때문
- 중심 좌표를 사용하는 이유
- 전체적으로 S * S * B * 5개의 값이 예측됨
- (x, y, w, h) : 예측한 bounding box의 해당 grid cell 내에서의 상대 중심 좌표와 상대 w h 비율
- NMS를 통한 중복된 bounding box를 제거 : Confidence score가 가장 높은 Bbox 추출
- Confidence score 기반 정렬 → 가장 높은 confidence score Bbox 선택 → 선택된 Bbox와 나머지 Bbox간 IOU를 계산 → 임계값 이하의 박스를 제거 및 반복 수행
- NMS를 통해 선택된 bounding box에 대한 클래스 확률 예측
\(P_r(Class_i | Object) * P_r(Object) * IOU_{truthpred} // = P_r(Class_i) * IOU_{truthpred})
Network Design
GoogLeNet 모델의 영감을 받아 구성되었으며, 24개의 convolution layers와 2개의 fully connected layers를 사용하였고, Inception module을 그대로 사용하는 대신 (1 * 1) reduction layer와 (3 * 3) convolution layer를 사용하였다.
Final Output의 shape은 (7 * 7 * 30) 이다.

YOLO Neural Network Architecture Training
논문에서는 사전 학습에 있어 20개의 convolution layers와 average pooling layer, fully connected layer를 사용하였고, training과 inference에 있어 Darknet framework를 사용했다.
YOLOv1의 Backbone은 Darknet Framework이다. GoogLeNet의 Inception Module에서 영감을 받아 (1 * 1) 과 (3 * 3) convolution layer를 사용하였지만, 이는 차원을 축소하고 특징을 추출하는 layer를 구성하여 네트워크의 효율성을 향상시키고 계산 비용을 줄이기 위한 '아이디어를 활용'한 측면이 강하다고 생각된다.
Detection 수행에 있어서는 4개의 convolution layers와 2개의 fully connected layers를 사용했다. 마지막 layer에서는 linear activation 함수를 사용했고, 다른 모든 layer에서는 Leak ReLU 함수를 사용했다.
[손실함수]
기존 R-CNN 계열의 모델이 classification 과 localization task에 있어 서로 다른 loss 함수를 사용했던 것과는 달리, YOLO의 손실함수는 SSE (Sum-squared error)를 사용한다. 하지만 SSE를 그대로 사용하게 되면,
- 직관적이고 간단하다는 점에서 쉽게 최적화가 가능하다는 장점이 있지만,
- localization error와 classification error의 가중치가 동일하다는 점에서 맞지 않고,
- 객체를 포함하고 있지 않은 grid cell의 confidence 값은 0이라는 점에서, 객체를 포함하고 있는 grid cell의 gradient power를 압도할 수 있는 문제가 생겨 균형적이지 못한 모델이 완성되는 문제가 발생할 수 있다.
이를 해결하기 위해 논문에서는 객체를 포함하고 있지 않은 grid cell의 영향력을 줄이고, 객체를 포함하고 있는 gird cell의 영향력을 강조하기 위해 가중치를 상이하게 설정한다.
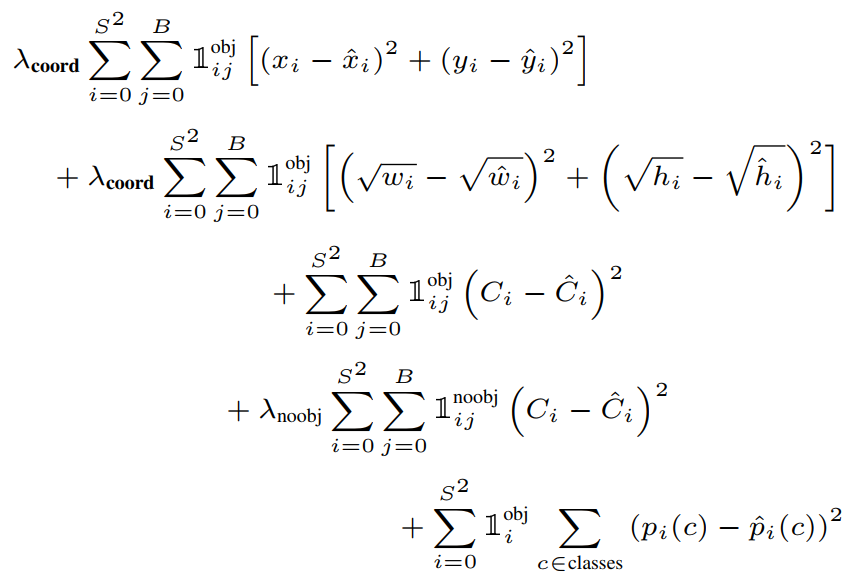
Total Loss Function _ Use SSE - Localization Loss : 예측된 bounding box의 (x, y, w, h)와 GT BOX와의 차이
- \(1^{obj}_{i j}) : i번째 grid cell의 j번째 Bbox가 객체를 예측하도록 할당 받았을 때 1 (confidence Score가 높아 살아남은 Bbox)
- \(\lambda_{coord}) : 논문에서는 5로 설정
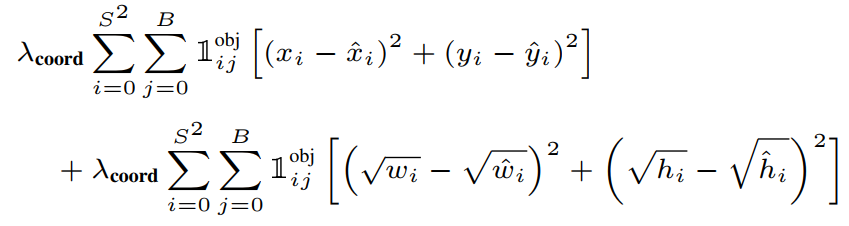
Localization Loss - Confidence Loss : 예측된 Bbox의 confidence socre와 실제 GTBox의 confidence score의 차이
- \(1^{noobj}_{i j}) : i번째 grid cell의 j번째 Bbox가 객체를 예측하도록 할당 받지 않았을 때 0
- \(\lambda_{noobj}) : 논문에서는 0.5로 설정
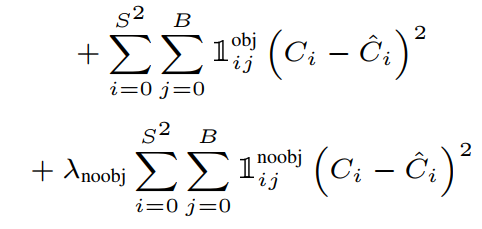
Confidence Loss - Classification Loss : gird cell에서만 계산되는 것으로, 최종 예측된 Bbox의 class 확률과 실제 class 확률의 차이
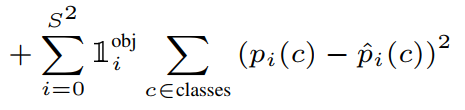
Classification Loss Limitation
각각의 grid cell에서 B개의 Bounding box를 예측하고, 1개의 클래스만 가져야 한다는 점에서 강력한 공간 제약이 발생한다는 한계점이 존재한다. (즉 하나의 grid cell 혹은 특정 Box에 여러 개의 객체가 존재하고, 여러 개의 객체를 동시에 Detection을 하고 싶어도 할 수 없다는 단점이 존재하는 것)
예측되는 Bbox의 크기와 모양은 훈련 데이터로부터 학습된다는 점에서, 비정형적인 사이즈의 새로운 데이터가 입력되었을 때 일반화에 어려움을 겪을 수 있다.
Bbox의 크기에 상관 없이 모두 동일하게 오류를 처리한다는 점에서 비효율적이라는 단점이 존재한다. (큰 상자에서의 오류는 작지만, 작은 상자에서의 작은 오류는 상대적으로 큰 오류로 간주되기 때문에 loss function 의 optimize 과정에서 계산 오차가 커지게 되는 문제점 발생)
<Summary>
YOLO는 One-Stage Object Detection model이라는 점에서 Unified Model이며 DPM Detection 모델들과는 달리 classfier를 사용하는 것이 아니라 regression의 관점에서 object detection을 수행.
가장 큰 특징은 input image에 대한 한 번의 연산을 통해 전체 이미지의 특징을 추출하고, 이를 통해 Bbox를 도출하고, confidence score와 GT box와의 coordinate의 차이, 최종 Bbox의 classification predicts score를 비교하여 object의 local과 classification을 동시에 수행하는 end-to-end model이다.
속도가 빠르고 모델 구성이 간단하다는 장점이 있으나, 정확도는 상대적으로 떨어진다는 문제가 지적되기도 한다. 또한 하나의 grid cell 혹은 bounding box에 복수의 객체가 존재하더라도 1개의 객체만 검출이 가능하다는 점과, Bbox의 크기에 상관 없이 loss 값을 optimize 한다는 점, 그리고 비정형적인 사이즈의 새로운 데이터를 검출하기에는 Bbox가 탄력적으로 변화할 수 없다는 단점이 지적되기도 한다.'deep learning > paper review' 카테고리의 다른 글