-
[review] Neural Machine Translation by Jointly Learning to Align and Translatedeep learning/paper review 2024. 3. 20. 00:36
원문 링크 : [1409.0473] Neural Machine Translation by Jointly Learning to Align and Translate (arxiv.org)

* Attention의 빠른 이해를 위한 개념
2024.03.20 - [deep learning/natural language process] - Attention Background
Attention Backgroud
1. Positional Encoding 정의 : 순서를 고려하지 않는 모델의 입력 sequence에 위치 정보를 제공하기 위한 encoding 방법 목적 : 모델이 단어의 순서를 이해하여 더 정확한 출력을 생성할 수 있도록 하기 위
ainow.tistory.com
* 핵심 요약
RNN Encoder-Decoder 모델의 경우 길이가 긴 문장의 번역 성능이 떨어지는 것이 확인되었고, 그 원인으로 input data가 fixed-length vector로 encoding됨에 따라 긴 문장 길이로 인한 정보의 소실 문제가 지적됨. 본 논문에서는 fixed-length vector로의 encoding을 극복하고, 번역에 있어 input data와 output data의 alingment를 decoder에서 자동적으로 수행하는 모델을 제안
- encoder 수준에서의 개선 : fixed-length vector 제한 극복
: bidirectional RNN을 통해 forward와 backward 방향으로 input data에 대한 hidden state를 추출하고, 이를 수직으로 concatenate하여 decoder에 context vector로 전달 → input data의 모든 정보를 포함한 context vector 전달
- decoder 수준에서의 개선 : ① Attention ② Alignment model ③ Backpropagation
① Attention : decoder에서의 hidden state와 encoder에서 전달된 context vector 정보를 바탕으로 attention value를 계산
② Alignment model : 계산된 attention value를 바탕으로 FFNN에서 target word를 alignment → attention value 계산 과정에서 softmax 함수를 사용하여 가중합을 구하기 때문에, 그 결과를 통해 자동적으로 target word를 alignment
③ Backpropagation : alignment를 하는 과정에서 특정 단어를 '선택'하는 것이 아니라 softmax 함수를 통해 전체 context vector를 고려했다는 점에서, backpropagation을 통한 학습을 가능케 함0. Abstract
encoder-decoder 기반의 architecture를 가진 신경망 기반의 기계 번역 모델들의 주요 bottleneck 현상을 극복하기 위한 architecture를 제안하는 논문으로, 고정된 길이의 encoding vector를 사용하지 않음으로서 alignment 추출 문제를 자동화하는 새로운 기계 번역 모델 제안
1. Introduction
일반적으로 encoder-decoder 기반의 기계 번역 모델들의 경우 encoder가 source sentence를 읽고 고정 길이의 vector로 encoding을 진행하면, decoder가 encoding vector에서 번역을 수행하는 것으로, 번역 타겟 문장이 적절한 번역 문장일 조건부 확률을 최대화하는 task라고 할 수 있다.
encoder-decoder 기반의 기계 번역 모델의 문제는 encoder가 source sentence를 fixed-length vector로 encode해야 한다는 것이다.
- fixed-length vector로의 encoding 과정에서 정보의 소실 문제 발생 가능
- source sentece의 길이가 길어질수록 fixed-lenght로 인한 정보의 소실을 극대화되어 성능이 급속도로 저하
본 논문에서 제안하는 모델의 경우 fixed-length vector로 encoding 하지 않으며, encoding된 벡터로부터 alignment extraction을 자동적으로 수행하는 모델
기존의 기계 번역 모델의 경우 훈련 과정에서 input source sentence에 대응되는 target sentence를 alignment 한 이후에 학습을 진행하였지만, attention model의 경우 모델이 자체적으로 대응되는 target sentence를 alignment 한다는 장점이 있으며, 이는 fixed-length vector로의 encoding을 하지 않는 방법으로 모델의 architecture가 구성되었기 때문에 나타난다.
2. Background : Neural Machine Translation
확률적 관점에서 신경망 기반의 기계 번역 모델은 주어진 source sentence에 대한 target sentence의 조건부 확률을 극대화하는 것과 동일하며, 이를 위해서는 source sentence와 target sentence의 쌍이 전제되어야 한다.
2-1. RNN Encoder-Decoder
- Encoder
- $\bold {x} = (x_1, ...\ , x_{T_x})$ → encoder의 hidden state $h_t = f(x_t, h_{t-1})$ → context vector $c = q({h_1, ///\ , h_{T_x}})$
- $h_t \in \mathbb R^n$이고, $f$와 $q$는 각각 비선형 활성함수
- Decoder : auto-regressive하게 다음 단어 예측
- context vector c
- 현재 시점 이전에 예측한 단어 집합
- decoder의 hidden state $s_t$
- $p(y_t\ |\ {y_1, y_2, ...\ , y_{t-1}}, c)\ =\ g(y_{t-1}, s_t, c)$
- $p(\bold {y})\ =\ \prod_{t=1}^T p( y_t\ |\ {y_1, y_2, ...\ , y_{t-1}}, c )$
일반적인 신경망 기반의 기계 번역 모델에서 RNN 기반의 Encoder-Decoder architecture를 사용하는 경우, Encoder와 Decoder의 작동 원리에 대한 설명에 해당.
Encoder의 경우, embedding layer를 거친 input data의 개별 token을 바탕으로 출력 값을 생성하며, 이 때의 출력 값은 이전 시점의 정보를 담고 있는 hidden state의 값을 활용한다.
Decoder의 경우, 기본적으로 auto-regressive하게 decoding을 수행하며, decoding을 위해 이전 시점에서 출력된 값과 encoder로부터 전달된 정해진 길이의 context vector를 사용한다. 이 때 context vector는 encoding의 마지막 시점에서 생성된 hidden state 값에 해당한다. ($h_t = f(x_t, h_{t-1})$)3. Learning to Align and Translate
본 논문에서 제안되는 새로운 신경망 기반의 기계 번역 architecture는,
- encoder의 경우 bidirectional RNN으로 구성되며,
- 번역 중에 source sentence를 검색하는 것을 emulate하는 decoder로 구성
3-1. Decoder : General Description
Auto-regressive 한 성격인 일반적인 Decoder와 동일하지만, target word인 $y_i$에 대해 개별적인 context vector $c_i$가 고려됨
- $p(y_i\ |\ y_1, ..., y_{i-1}, \bold {x}) = g(y_{i-1}, s_i, c_i)$ where s_i = f(s_{i-1}, y_{i-1}, c_i)
각 시점에서 고려되는 context vector $c_i$는 encoder에서 매핑된 hidden state에 의존하며, i번째 단어 주변 부분에 대한 강한 attention이 포함되어 있다. contect vector는 가중합을 통해 계산된다.
- $e_{ij} =\alpha(s_{i-1}, h_j)$ : FFNN인 alignment model $\alpha$로 source sentence의 j번째 단어와 target sentence의 i번째 단어와의 연관성 점수
- $\alpha_{ij}={\text {exp}(e_{ij}) \over \sum_{k=1}^{T_x} \text {exp}(e_{ik})}$ : $h_j$의 가중치로, source sentence의 j번째 단어와 target sentence의 i번째 단어와의 연관 확률
- $c_i = \sum_{j=1}^{T_x} \alpha_{ij}h_j$ : $\alpha_{ij}$와 $h_j$의 가중합
즉, Decoder에서는 translate과 동시에 FFNN을 통해 source sentence에서 attention할 부분을 결정 _ emulate searching through source sentence
3-2. Encoder : Bidirectional RNN for Annotating Sequence
Encoder에서는 Decoder에서 사용할 annotation을 계산
bidirectional RNN을 사용하는 이유는, forward와 backward를 모두 고려하여 폭 넓은 정보를 활용하여 성능 예측 성능을 향상시키기 위함
annotation 은 forward와 backward hidden state를 모두 concatenate한 것으로, 이를 통해 fixed-length vector로의 encoding 과정에서 발생하는 정보의 소실 문제를 극복하며 seq2seq 모델의 약점을 극
4. Experiment Settings
영어-프랑스어 번역 작업에서 본 논문의 모델을 사용하여 성능을 평가
- RNN Encoder-Decoder 모델 : RNNencdec
- 본 논문에서 제안하는 모델 : RNNsearch
5. Results
5-1. Quantitative Results

Table 1 : BLEU scores of the trained models computed on the test set. RNNendec과 RNNsearch의 성능을 비교해본 결과 RNNsearch의 성능이 더 우수.
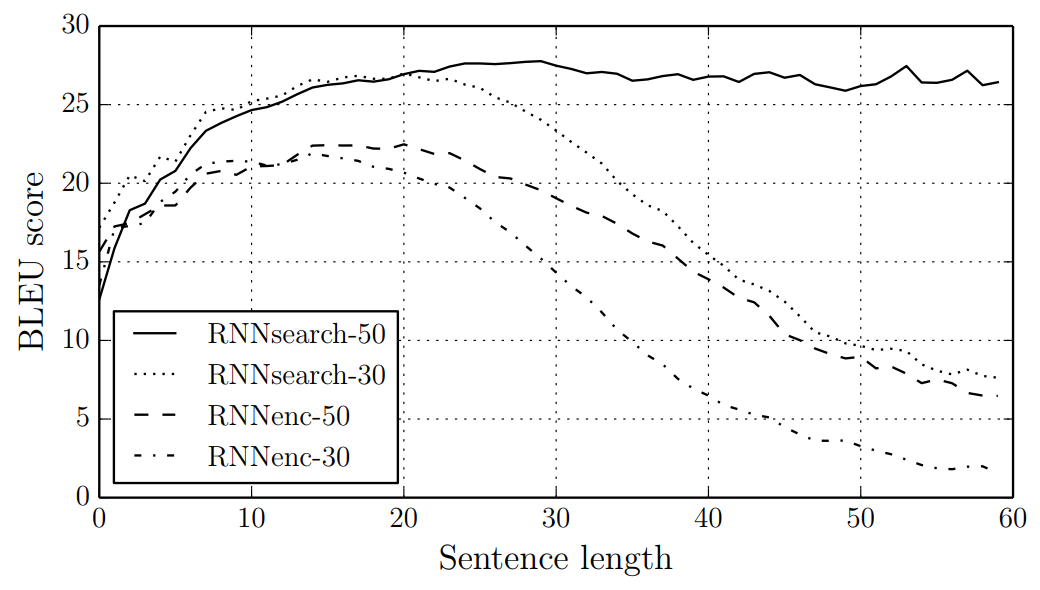
Figure 2 : BLEU scores of the generated translations on the set with respect to the lengths of the sentences. 문장 길이가 변화함에 따른 성능 평가의 결과 fixed-length vector를 사용하지 않는 RNNsearch가 더 우수한 것으로 확인되며, 이를 통해 fixed-length vector의 사용이 문장 길이가 길어짐에 따라 발생하는 성능 저해 문제의 원인임을 확인
5-2. Qualitative Analysis
5-2-1. Alignment
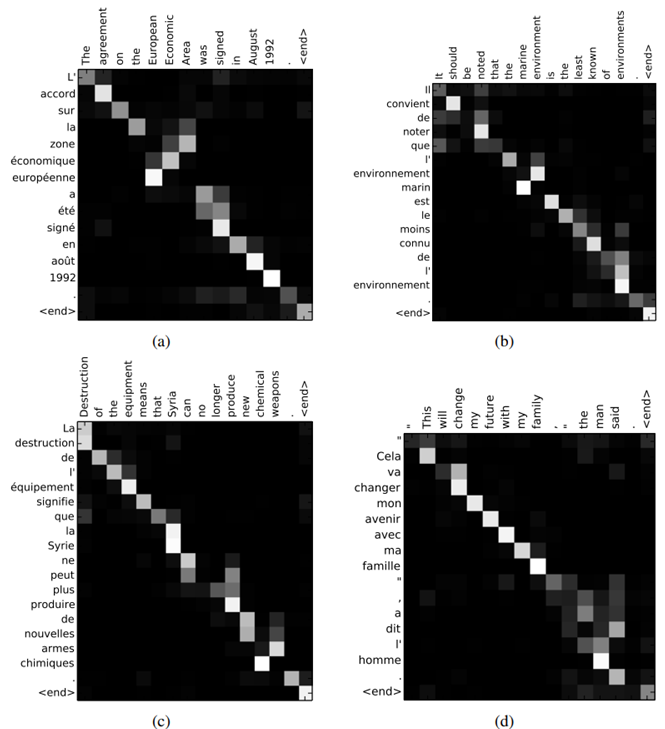
Figure 3 : Four sample alignments found by RNNsearch-50. Figure 3는 annotation weights $$\alpha_{ij}의 시각화한 것으로, 전체적인 alignment가 잘 수행되었다는 점에서, alignment model이 잘 작동하고 있음을 확인
5-2-2. Long Sentence
길이가 긴 문장에 대한 번역 성능 역시 RNNencdec보다 RNNsearch가 더 우수하게 평가됨.
Attention mechanism의 핵심은 fixed-length vector의 문제를 극복하여 모델이 자동적으로 target word와 input word를 alignment할 수 있도록 만들었다는 점에 있는 것으로 보임
'deep learning > paper review' 카테고리의 다른 글