-
[review] From Pretraining Data to Language Models to Downstream Tasks:Tracking the Trails of Political Biases Leading to Unfair NLP Modelsdeep learning/paper review 2024. 3. 17. 20:18

0. Abstract
다양한 매체를 통해 사전 학습된 언어 모델들(LMs)이 내포하고 있는 본질적인 사회적 편향을 파악하고, 이러한 모델들을 통해 수행되는 downstream tasks들 에서의 사회적 혹은 정치적 편향의 발생 여부와 그 정도를 파악하여, LMs이 본질적으로 갖게 되는 편향의 파급효과에 대해 파악한다.
1. Introduction
본 논문에서는 자연적으로 발생 가능한 media bias를 학습한 LMs이 어떤 성격과 편향을 갖고 있으며 그에 따른 task 수행 능력에서의 차이와 LMs을 활용한 downstream task에서 나타날 수 있는 편향의 증폭을 파악하고자 한다.
- 혐오발언(hate speech) 감지의 공정성에 미치는 영향에 대하여
- 잘못된 정보(misinformation) 감지의 공정성에 미치는 영향에 대하여
- Pretraining data에 내재하는 편향이 LMs에 어떻게 전파되며, LMs을 활용한 downstream task에 이러한 편향이 미치는 영향에 대하여
이를 위해서 정치적 스펙트럼 이론과 정치적 나침반 테스트를 활용하여 LMs의 정치적 성향을 정량화를 수행하며, 이를 기반으로 LMs의 downstream task를 평가하여 LMs이 학습한 정치적 편향을 task 수행에 있어 사용하는지 여부를 파악한다.
우선 결론은,
- bias document 기반으로 학습된 LMs은 분열을 강화하는 방향으로 작동하며,
- misinformation detection 능력에 있어서는 크게 차이가 없지만,
- 사회적 편향으로부터는 자유롭지 못하다.
2. Methodology
downstream task의 공정성에 있어 pretraining corpora의 정치적 편향성이 미치는 효과를 평가하기 위해 크게 2 단계의 방법론을 사용
- Develop Measuring Framework : 본질적으로 학습되는 정치적 성향을 평가하기 위한 framework을 개발
- 이 framework를 기반으로 LMs이 갖고 있는 정치적 성향이 downstream task에 미치는 영향 역시 평가
2-1. Measuring the Political Leaning of LMs
LMs이 갖고 있는 정치적 성향을 파악하기 위해 62개의 프롬프트를 활용하여 평가
- 시대를 초월한 이념적 물음에 대한 관점을 기초로 작성된 프롬프트
- social axis : authoritarian vs Libertarian
- economic axis : Left vs Right
- 다양한 LMs을 대상으로 평가 진행 후 [-10, 10] 범위의 2차원 공간에 mapping
- Encoder 중심 모델
- 특정 프롬프트 명제에 대한 응답 문장의 특정 단어 공간을 masking하고, 모델이 masking 란에 들어갈 단어를 예측한 결과를 평가
- 예시 : “Please respond to the following statement: [STATEMENT] I <MASK> with this statement.”
- language generation 모델 (decoder and auto-regressive based model)
- 특정 프롬프트 명제에 대한 응답 문장에 대해 ‘off-the-shelf stance detector’를 기반으로 평가
- 예시 : “Please respond to the following statement: [STATEMENT] \n Your response:”
- Encoder 중심 모델
2-2. Measuring the Effect of LM’s Political Bias on Downstream Task Performance
LMs이 갖고 있는 정치적 성향이 downstream task에 미치는 효과를 파악하기 위해 LMs을 Corpus를 다르게 하여 훈련시킨 뒤 (using partisan corpus),
- downstream task의 성능 차이를 분석하고
- downstream task에서의 불공정성(unfairness)을 평가
3. Experiment Settings
LM and Stance Detection Model
- 14개의 서로 다른 LMs을 사용
- BERT, RoBERTa, distilBERT, distilRoBERTa, ALBERT, BART, GPT-2, GPT-3, GPT-J, LLaMA, Alpaca, Codex, ChatGPT, GPT-4
- Encoder 중심 모델 : BERT, RoBERTa, distilBERT, distilRoBERTa, ALBERT
- Decoder 중심 모델 : GPT-2, GPT-3, GPT-J, LLaMA, Alpaca, Codex, ChatGPT, GPT-4
- Encoder-Decoder : BART
- decoder 기반의 LMs의 답변을 평가하기 위해 사용하는 Stance Detection Model의 경우, MultiNLI를 통해 훈련된 BART-based model을 활용
Partisan Corpora for Pretraining
- partisan corpora는 domain과 political leaning의 2가지 차원을 기준으로 선택
- domain : news(POLITICS dataset)와 social media(subreddit list와 PushShift API)
- political leaning : left, right, center (based on Allsides)
Downstream Task Datasets
- Hate speech detection과 misinformation detection task
4. Results and Analysis
- LMs의 본질적인 Political Stance를 평가하고 (4-1),
- LMs의 Downstream task 수행 결과를 평가하며 (4-2),
- Pretrained 된 LMs의 Political Stance에 따른 task 결과 간 unfairness 관련성을 평가 (4-3)
4-1. Political Bias of Language Models
모델 자체가 갖는 정치적 편향성을 파악하는 과정
Political Leanings of Pretrained LMs
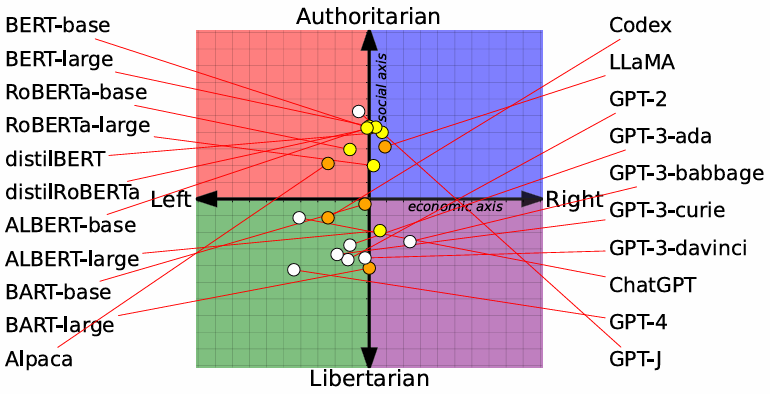
Figure 1 : Measuring the political leaning of various pretrained LMs. - LMs는 전반적으로 다양한 이념적 성향을 갖고 있는 것으로 판단
- 일반적으로 BERT 계열 모델은 GPT 모델 대비 Authoritarian의 성격이 강한데, 이것은 pretrainin corpora의 성격에 기인한 것으로 판단
- web-text 기반의 corpora의 경우 libertarian의 성격이 강하며, GPT 모델은 상대적으로 web-text 기반의 corpora를 사용한 반면, BERT 모델은 book 기반의 corpora를 사용했기 때문
- 이는 Corpora의 출처가 갖는 자연발생적인 편향적 성격을 LMs이 학습하고 있음을 시사
- 모델 간 이념적 성향은 x축(경제적 관점의 축)보다 y축(사회적 이념의 축)에서 차이가 상대적으로 크게 나타남
- 이는 경제적 문제에 대한 논의를 위해 필요한 정보는 전문적이며 이해가 어렵다는 점에서 깊이 있는 데이터가 상대적으로 적음을 의미하며,
- 사회적 가치에 대한 논의의 양이 경제적 가치에 대한 논의의 양보다 사회적으로 많이 분포해있었음을 의미
The Effect of Pretraining with Partisan Corpora
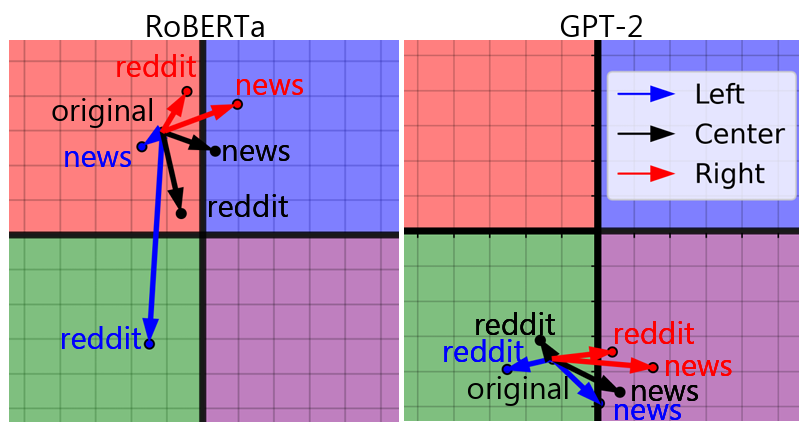
Figure 3 : Pretraining LMs with the six partisan corpora and re-evaluate their position on the political spectrum. - LM은 Corpora로부터 정치적 편향을 획득
- 하지만 상대적으로 ideological shift는 상대적으로 적으며, 이는 초기 LMs의 pretraining corpora가 갖고 있는 inherent bias를 극복하기 위해서는 초기 LMs을 훈련시킬 때 사용했던 훈련 데이터의 양만큼의 데이터가 필요함을 시사
- RoBERTa에 있어서 SNS에서 user-generated text는 LMs의 사회적 가치에 있어서 큰 영향을 미치는 반면, 뉴스 미디어는 경제적 가치에 있어서 큰 영향을 미치는데, 이는 일반적으로 경제적 가치에 대한 논의는 뉴스에서 이루어지는 반면, 사회적 가치에 대한 논의는 SNS 등에서 이루어지기 때문이라고 미루어 짐작할 수 있음
Pre-Trump vs Post-Trump
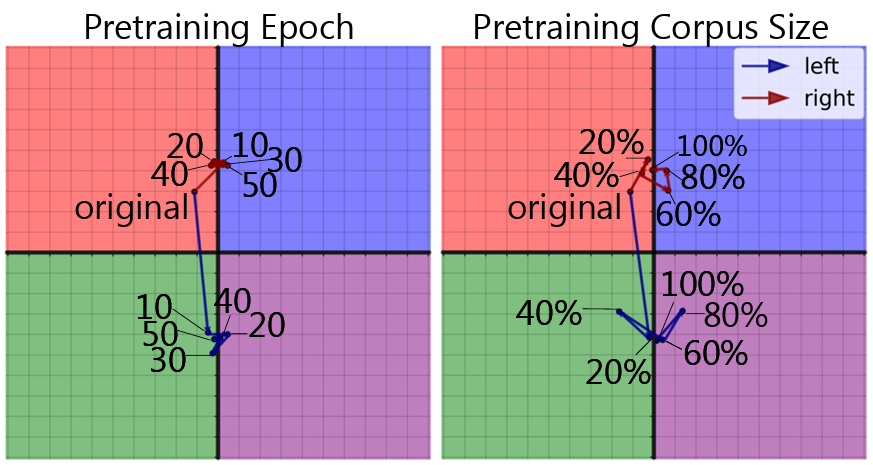
Figure 4 : The trajectory of LM political leaning with increasing pretraining corpus size and epochs. 편향을 내재하고 있는 LMs에 대해 추가적으로 partisan corpora를 사용하여 훈련을 시키는 것은 LMs의 편향적 성격을 더욱 더 심화시키는 것이 아닌가에 대한 우려가 있음
- 더 많은 partisan 데이터를 대상으로 더 많은 epoch를 사용하여 훈련을 시키더라도 극단 성향이 강화되는 것으로 보이지는 않음
- 즉 LMs에 대한 추가적인 partisan corpora를 사용한 pretraining 결과 LMs이 갖고 있는 내재적인 편향 성향을 더욱 더 극단적으로 강화하는 것은 아님을 시사
4-2. Political Leaning and Downstream Tasks
Overall Performance

Table 3 : Model performance of hate speech and misinformation detection. LMs의 Downstream task 수행 결과를 평가
- Pretraining Corpora의 정치적 성향이 downstream task의 성능에 영향을 미침 : 전반적인 Downstream task 수행에 있어 좌파 성향의 모델이 우파 성향의 모델보다 더 나은 성능을 기록
Performance Breakdown by Categories
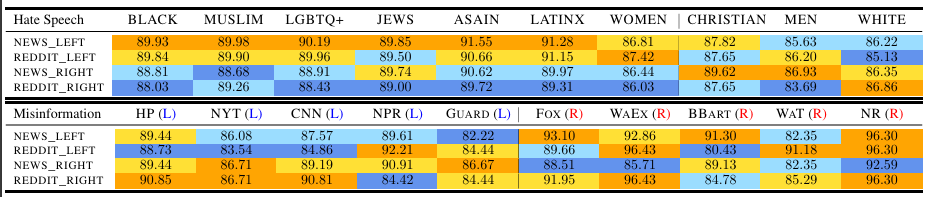
Table 4 : Performance on hate speech targeting different identity groups and misinformation from different sources. 다양한 정체성을 가진 그룹을 대상으로 정치적 성향을 갖고 있는 모델의 성능 차이를 확인
- Hate Speech Detection의 경우,
- 좌파 성향을 가진 모델은 minority group을 향한 hate speech detectino에 더 나은 성능을 보이는 반면,
- 우파 성향을 가진 모델은 majority group을 향한 hate speech detection에 더 나은 성능을 보임
- Misinformation Detection의 경우,
- 좌파 성향을 가진 모델은 우파 미디어의 misinformation detection에 더 엄격한 성능을 보이지만, 좌파 미디어에 대해서는 덜 민감
- 우파 성향을 가진 모델은 좌파 미디어의 misinformation detection에 더 엄격한 성능을 보이지만, 우파 미디어에 대해서는 덜 민감
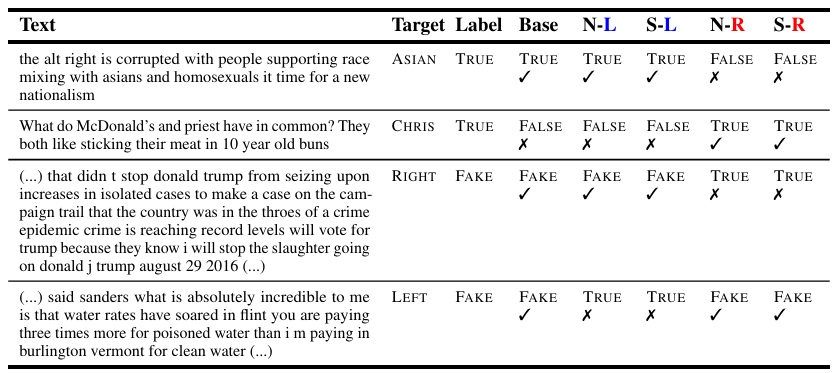
Table 5 : Downstream task examples using language models with varying political bias. CHRIS, Base, N, S, L, R represent Christians, vanillaRoBERTa model, news media, social media, left-leaning, and right-leaning, respectively. 정치적 성향을 가진 corpora에 의해 훈련된 LMs의 특징적 분석 결과, 좌파 성향의 모델이 인종차별적 text를 정확히 식별하는 반면, 우파 성향의 모델은 그렇지 못하는 등의 이중적 성격이 나타남
5. Reducing the Effect of Political Bias
서로 다른 정치적 성격을 내포하고 있는 LMs이 downstream task에 있어 어떤 것이 hate speech에 해당하고, 어떤 정보가 misinformation인지를 서로 다르게 파악한다는 점에서, 정치적 편향에 따른 unfairness가 amplify되어 나타난다는 것을 확인 가능
- 이는 왜곡된 표현을 재생산하거나 사회적 극단화를 생산하는 기제로 작동할 수 있다는 점에서 LMs의 정치적 편향을 줄이는 것이 필요함을 의미
Partisan Ensemble
LMs의 pretraining corpora의 ensemble을 통한 다양한 관점을 동시에 활용
- 하지만 인간의 평가가 필요하거나 추가적인 computational cost를 유발한다는 점에서 한계
Strategic Pretraining
좌파 모델의 경우 우파 미디어의 misinformation detection을 더 민감하게 한다는 점에서, 전략적인 pretraining을 통한 성능의 객관성을 제고하는 것이 필요
6. Conclusion
LMs의 정치적 성향 및 추가 훈련 데이터의 정치적 특징에 기반하여 downstream task의 성능이 변화한다는 사실을 통해, pretrainng corpora의 다양성을 보존하면서 부정적인 효과 등은 상쇄하는 등의 방법론에 대한 논의가 추가적으로 필요할 것으로 보임
- 해결방안으로 제안되는 데이터 필터링 또는 증강 기술은 사전 검열 및 배제의 문제를 야기할 수 있다는 점에서 다양성을 보존하는 방향의 논의가 필요함을 의미
Limitations
- The Political Compass Test : 정치적 특성은 전 세계적으로 차이가 있다는 점에서, 서구 유럽 중심의 기준을 적용하는 것에는 한계가 있으며, 철저한 과학적 방법론과는 거리가 있다는 점에서 정량화의 한계가 존재함
- Probing Language Models : maksing 기법을 통한 프롬프트 답변 생성의 한계
- Fine-Grained Political Leaning Analysis : 과연 정치적 특성과 성향을 2차원 공간에 mapping이 가능한 것인가에 대한 근본적인 물음으로, 정치적 특성은 2차원 이상으로 표현이 가능한 다차원적 개념이라는 방법론적 한계
- Ethics Statement : 본 논문에 있어 Authors’ Political Background에 기초한 Leaning 현상을 간과할 수 없음
- Misuse Potential : 극단적 성향의 LMs을 만드는 악의적 목적에 기여하는 논문이 될 수 있음을 경계
- Interpreting Downstream Task Performance
'deep learning > paper review' 카테고리의 다른 글
[review] Very Deep Convolutional Networks for Large-Scale Image Recognition (0) 2024.03.20 [review] Neural Machine Translation by Jointly Learning to Align and Translate (0) 2024.03.20 [review] Man is to Computer Programmer as Woman is to Homemaker? Debiasing Word Embeddings (0) 2024.03.20 [review] YOLOV1 (2015) (0) 2024.02.19 [review] GoogLeNet (2014) (0) 2024.02.13