-
[review] Very Deep Convolutional Networks for Large-Scale Image Recognitiondeep learning/paper review 2024. 3. 20. 00:52
원문 링크 : [1409.1556] Very Deep Convolutional Networks for Large-Scale Image Recognition (arxiv.org)
Very Deep Convolutional Networks for Large-Scale Image Recognition
In this work we investigate the effect of the convolutional network depth on its accuracy in the large-scale image recognition setting. Our main contribution is a thorough evaluation of networks of increasing depth using an architecture with very small (3x
arxiv.org

핵심 요약
- 3x3 convolution filter를 가진 network을 이용해 깊이를 증가시킨 모델을 평가
- 깊이를 16-19 layer로 늘려 이전 모델들보다 개선됨을 증명
1. Introduction
- ConvNet 아키텍처 설계의 또 다른 중요한 측면인 깊이에 대해 설명
- 아키텍처의 다른 매개변수를 수정하고 더 많은 컨볼루션 레이어를 추가하여 네트워크의 depth를 꾸준히 증가시킨다.. 이는 모든 레이어에서 매우 작은(3x3) 컨볼루션 필터를 사용하기 때문에 가능.
- LSVRC Classification 및 localisation task에서 SOTA를 달성할 뿐만 아니라 다른 이미지 인식 데이터 세트에도 더 정확한 ConvNet 아키텍처를 제시.
2. ConvNet Configurations
2-1 Architecture
- ConvNet에 대한 입력은 고정 크기 224x224 RGB 이미지.
- 이미지는 컨볼루션 레이어 스택을 통과하며 여기서 매우 작은 3x3 필드가 있는 필터 사용.
- 컨볼루션 stride은 1픽셀로 고정됩니다. 레이어 입력은 공간 해상도가 컨볼루션 후에 보존. 즉, 3x3 conv 레이어의 경우 패딩은 1픽셀.
- Max pooling은 stride 2로 2x2 pixel window에서 수행.
- 컨볼루션 레이어 스택에는 3개의 완전 연결 레이어(fully connected layer)이 존재. 처음 두 개의 레이어는 각각 4096개의 채널을 갖고 세 번째 레이어는 1000 class에 대한 분류를 수행하므로 1000개의 채널을 가짐.
- 마지막 레이어는 soft-max 변환 레이어.
- 마지막가 완전 연결 레이어를 제외한 모든 레이어에는 ReLU를 적용.
2-2 Configurations
- ConvNet 구성
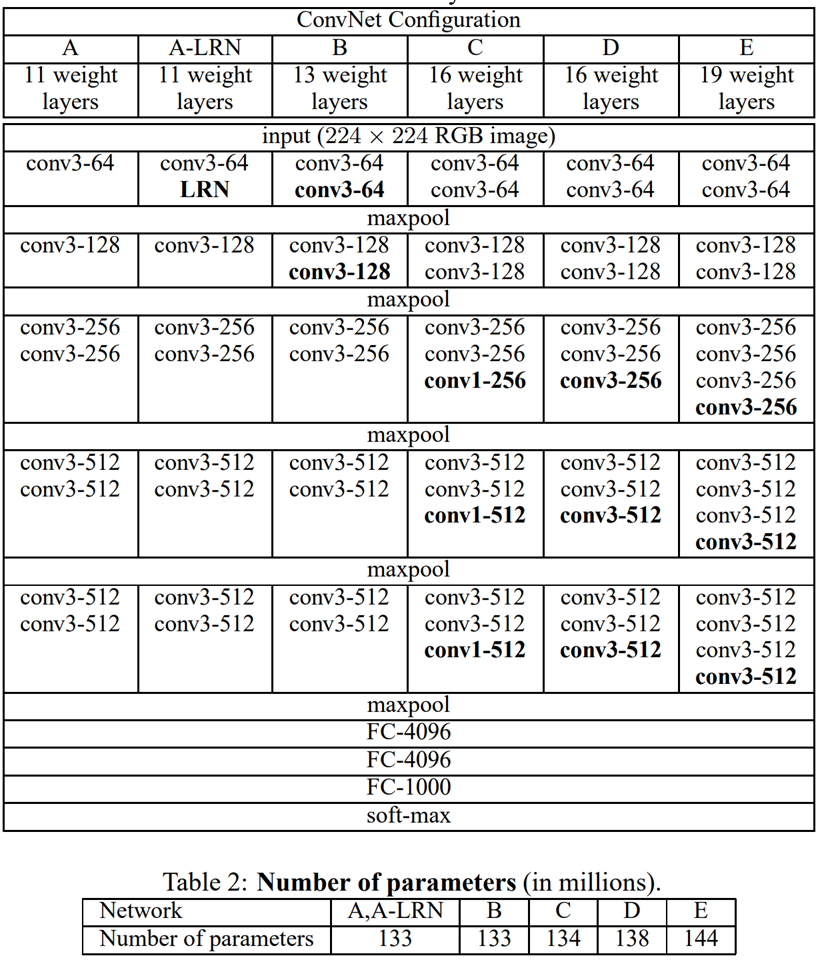
- A~E의 모든 구성은 섹션 2.1에 제시된 일반 설계를 따르며 depth 부분에서만 차이 존재.
- 네트워크 A의 11개 가중치 레이어(8개의 컨볼루션 레이어 및 3개 FC 레이어)에서 네트워크 E의 19개 가중치 레이어(16개의 컨볼루션 및 3개 FC 레이어)까지 존재.
- 컨볼루션의 너비 레이어(채널 수)은 첫 번째 레이어 64개에서 시작하여 각각의 맥스 풀링 레이어 이후 2배씩 512에 도달할 때까지 증가.
2-3 Discussion
- 전체 네트워크에서 매우 작은 3x3 receptive field 사용, 모든 픽셀에서 입력으로 컨볼루션됨 (stride1).
- 한 개의 7x7 컨볼루션 레이어 대신 3개의 3x3 컨볼루션 레이어를 사용함으로서 결정함수의 비선형성을 증가시키며, 이를 통해 피처(feature)의 식별성 제고.
- 3개의 3x3 컨볼루션 레이어 스택이 C개의 채널을 가지고 있다고 가정하면 스택은 $3(3^2C^2 ) = 27C^2$ 가중치에 의해 파라미터화 되는데 단일 7x7 레이어는 $72C^2 =49C^2$ 매개변수가 필요해 거의 81%가 더 필요.
3. Classification Framework
3-1 Training
- 학습은 역전파(back-propagation) 기반으로 미니 배치 경사하강법(gradient descent)을 사용하여 수행.
- Batch Size : 256
- Momentum : 0.9
- L2 regularization : $5 \times 10^{-4}$
- 학습률(Learning rate): $10^{-2}$, valiation에 대한 accuracy 향상되지 않으면 매번 학습률을 10배 감소, 370K 반복 이후 학습 중단(74 epoch)
- Weight decay : $5\times10^{-4}$
- Dropout : 0.5
- 잘못된 초기화는 많은 수의 컷오프으로 인해 학습을 지연시킨다는 점에서 네트워크 가중치의 초기화는 매우 중요.
- 학습 지연 막기 위해 무작위 초기화로 교육될 정도로 얕은 구성을 학습하는 것으로 시작.
- 그 후 깊은 architecture을 훈련할 때, 처음 4개의 컨볼루션 레이어와 마지막 3개의 FC 레이어를 네트워크의 레이어로 초기화. (중간 layer들은 무작위로 초기화 됨)
- 224x224 크기의 ConvNet 입력 이미지를 얻기 위해 재조정된 학습 이미지(rescaled training image)를 무작위로 crop.
- Multi-scale training
- 멀티 스케일 훈련의 또 다른 방법은 가장 작은 이미지 측면을 무작위로 샘플링하여 각 훈련 이미지를 개별적으로 다시 스케일링하는 것.
- $[S_{min};S_{max}]$ ($S_{min} =256, S_{max} =512$) 에서 무작위로 S 추출해 학습 이미지를 개별적으로 스케일한다는 점에서 훈련 세트 증강으로 간주 가능.
3-2 Testing
- 테스트 시 학습된 ConvNet과 입력 이미지가 주어지면 다음과 같은 방식으로 분류.
- 가장 작은 면이 Q>224와 같도록 등방성으로 재조정되며, 이는 반드시 S와 같지만은 않음.
- 재조정된 테스트 이미지에 네트워크를 조밀하게 적용. (첫 번째 FC 레이어는 7x7 컨볼루션 레이어로, 마지막 두 FC 레이어는 1x1 컨볼루션 레이어로)
- 전체 크기(full-size) 입력으로 각 레이어의 필터를 컨벌루션하여 전체 이미지에 적용.
- 마지막으로 이미지에 대한 클래스 점수의 고정 크기 벡터를 얻기 위해 클래스 점수 맵이 공간적으로 평균화.
- 또한 이미지를 수평으로 뒤집음으로써 테스트 세트 확대를 사용.
3-3 Implementation Details
- Multi-GPU 학습 은 각 GPU에서 병렬로 처리되는 여러 GPU 배치들로 각 학습 이미지를 분할하여 수행.
- GPU 배치 gradient 계산된 후 평균을 구하여 전체 배치의 gradient를 계산. gradient 계산은 GPU 간에 동기화되므로 결과는 단일 GPU에서 훈련할 때와 정확히 동일.
- 4-GPU 시스템에서 단일 GPU 시스템보다 속도가 3.75배 향상 시킨다는 것을 발견.
4. Classification Experiments
- ILSVRC-2012 dataset에 대해 설명된 ConvNet architecture가 이뤄낸 image classification 결과를 제시.
- 데이터 세트에는 1000개 클래스의 이미지가 포함되어 있으며 세 개(학습 1.3m, 검증 50k, 테스트 100k images)의 집합으로 분할.
- Classification performance는 2가지 오류 척도로 평가.
- top-1 error : 다중 클래스 분류 오류, 즉 잘못 분류된 image의 비율
- top-5 error : 실측 범주가 상위 5개 카테고리들 밖에 있는 image의 비율
- 성능 평가
- 단일 테스트 스케일에서 ConvNet 성능
- 로컬 response normalization(A-LRN 네트워크)을 사용해도 모델 A에서 개선되지 않는다는 점에서 더 깊은 아키텍처 (B-E)에서 normalization 미사용.
- A의 11개 레이어에서 E의 19개 레이어로 ConvNet depth가 증가함에 따라 classification error가 감소하며, 특히 동일한 depth에도 불구하고 구성 C(3개의 1 × 1 컨볼루션 레이어 포함)은 3 × 3 컨볼루션을 사용하는 구성 D보다 성능이 더 나쁘다는 특징 확인 가능.
- 단일 테스트 스케일에서 ConvNet 성능
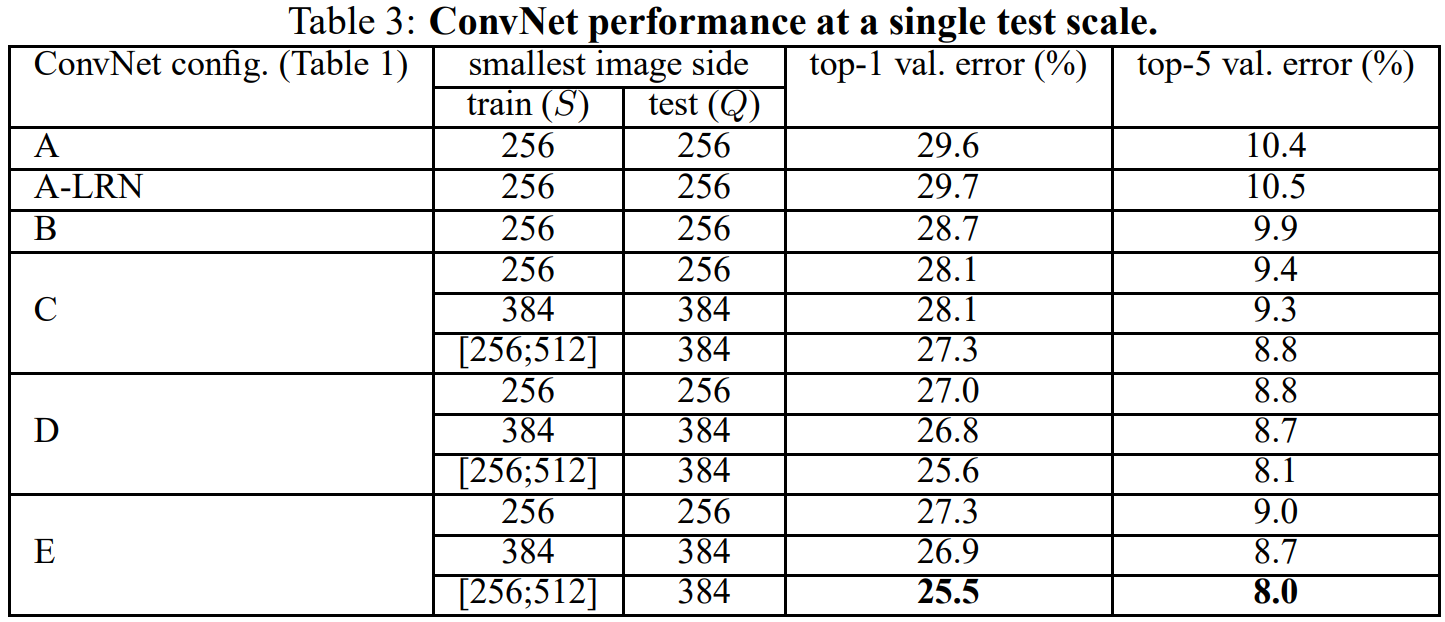
- 멀티 테스트 스케일에서 ConvNet 성능
- 스케일 지터링의 영향을 평가. 테스트 이미지의 여러 재조정 된 버전에 대해 모델을 실행하는 것으로 구성.
- 결과는 스케일 지터링이 더 나은 성능으로 이어진다는 것을 보여주며, 이전과 마찬가지로 가장 깊은 구성(D 및 E)이 가장 잘 수행되며 스케일 지터링은 고정된 가장 작은 면을 사용한 훈련보다 낫다는 결과 확인 가능.
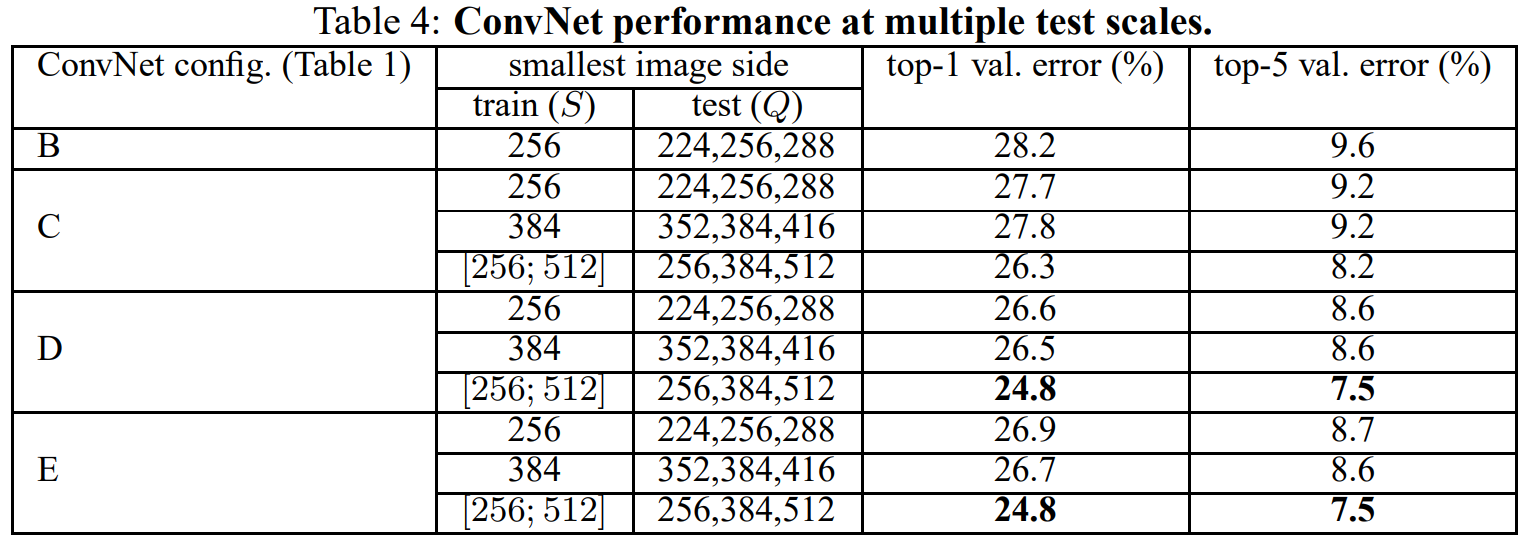
- 여러 ConvNet 퓨전 결과
- soft-max 클래스 후방을 평균화하여 여러 모델의 출력을 결합.
- 7개의 모델의 예측을 결합했음에도 불구하고 완전히 훈련된 2개의 다중 스케일 모델의 결합에 비해 정확도가 떨어진다는 특징.
5. Conclusion
VGG-Net은 기존의 Convolutional 아키텍쳐보다 작은 receptive field 및 최대 19 depth의 레이어를 설계하여 좋은 성능을 만들었다고 볼 수 있습니다.이 결과는 시각적 표현에서 depth의 중요성을 다시 한 번 확인시켜 줍니다.
'deep learning > paper review' 카테고리의 다른 글