-
[review] Do Androids Laugh at Electric Sheep? Humor "Understanding" Benchmarks from The New Yorker Caption Contestdeep learning/paper review 2024. 3. 21. 18:31
Do Androids Laugh at Electric Sheep? Humor "Understanding" Benchmarks from The New Yorker Caption Contest
Large neural networks can now generate jokes, but do they really "understand" humor? We challenge AI models with three tasks derived from the New Yorker Cartoon Caption Contest: matching a joke to a cartoon, identifying a winning caption, and explaining wh
arxiv.org

* Insight
LLM을 통해 다양한 task를 수행하면서, 다양한 언어를 이해하고 생성하는 과제에 대해 좋은 성능을 내고 있는 만큼, 언어만 이해해서는 제대로 수행할 수 없거나 언어를 정확히 이해하고 있는지 여부에 관한 task로 관심사가 이동하고 있는 것으로 보임. 본 논문은 humor라는 추상적인 개념 (혹은 감정적인 개념)을 멀티모달 LLM이 이해하고 이를 바탕으로 새로운 prompt를 생성할 수 있는지 여부를 확인하는 논문으로, 과연 감정적 단어를 어떻게 인식하고, 이를 이미지와 어떻게 연관시키며, 이러한 개념들을 활용하여 새로운 prompt를 생성할 수 있을만큼 창의적인지 여부를 평가하는 지표를 도출하려는 시도라고 생각됨.
0. Abstract
오늘날의 LLMs은 유머를 새롭게 생성해내지만, 과연 그러한 유머를 이해하고 생성하는가에 대한 질문에서 시작된 논문
본 논문에서는 크게 3가지의 task를 multi-modal model과 language-only model을 사용하여 진행
- cartoon에 joke를 매칭하는 task, 우승 caption을 인식하는 task, 우승 caption이 왜 재미있는가를 설명하는 task
- multi-modal model : cartoon 이미지에 대한 이해를 위한 모델
- language-only model : 인간 수준에서 시각적 장면에 대한 이해를 다측면으로 표현하기 위한 모델
결론적으로 두 모델의 세 task에 대한 성능은 인간의 능력에 비해 약 30% 떨어지는 것이 확인
1. Intorudction
The New Yorker cartoon caption contest를 통해 LLMs이 유머를 어떻게 이해하는지를 탐구하기 위한 논문으로, AI와 인간 사이에 humor를 이해하는데 격차가 있다는 것을 드러낸다.
- Contest 진행 방식 : 캡션 없는 만화 이미지를 게시하고, 독자들에게 가장 재미있는 영어 캡션을 제출하도록 하며, 가장 재미있는 이미지-캡션 조합이 승자가 되는 contest
LLMs 모델을 활용하여 만화에 caption을 달고, 가장 재미있는 catpion을 인식하고, 그 이유를 기술하는 task를 통해 모델의 이해력을 평가하고, humor의 이해 가능 여부를 test.
2. Datasets and Task Setups
Corpus : 14년 간의 데이터를 바탕으로 하며 아래 데이터를 바탕으로 한다.
- caption이 없는 cartoon
- 해당 cartoon에 대한 제출된 captions
- 결선 진출자
- 일부 contest에 대해 수집된 품질 추정치
2-1. Task Setups

Figure 1: We formulate three tasks using over a decade of New Yorker caption contests. - Matching : 모델이 cartoon과 winning caption을 matching 시킬 수 있는지를 확인
- matching 과정에서 문자 그대로의 text를 넘어선 reasoning 혹은 외부 지식(배경 지식)이 필요한 경우도 있음
- accuracy를 사용하여 평가
- matching 과정에서 문자 그대로의 text를 넘어선 reasoning 혹은 외부 지식(배경 지식)이 필요한 경우도 있음
- Quality Ranking : 모델이 높은 평가를 받은 caption을 식별할 수 있는지를 확인
- 결선에 오른 caption과 오르지 못한 caption을 비교하여 선택하도록 유도
- accuracy를 사용하여 평가
- 결선에 오른 caption과 오르지 못한 caption을 비교하여 선택하도록 유도
- Explanations : 모델이 특정 caption과 cartoon의 조합이 재미있는 이유에 대해 인간만큼 설명을 생성해낼 수 있는지를확인
- caption을 이해하지 못하는 사람에게 설명하듯 몇 문장으로 explanation을 작성하도록 prompt
- 저자가 작성한 prompt와 모델이 생성한 prompt 쌍이 사람(judge)에게 주어졌을 때, 저자가 작성한 prompt에 선호를 보이지 않는다면 모델이 성공적으로 해당 task를 수행했다고 판단
- NYAcc(New Yorker editors selections)와 CrowdAcc(Crowd selections)를 사용하여 평가
- 3-2의 가설 평가를 평가하기 위해 human evaluation을 진행하며, 이를 보완하는 목적의 평가지표도 함께 사용 (Appendix-E in Paper)

Figure 2: Instances of our three tasks. - Experiment Settings : From Pixels(FP)와 From Description(FD)
- From Pixels(FP) : vision+language model이 test 시점에서 이미지 처리를 수행할 때 cartoon image 그 자체에만 접근 가능하도록 설정
- From Description(FD) : vision task를 수행할 수 없어 cartoon에 대한 annotiatons 만을 활용하도록 설정
2-2. Annotation of cartoons
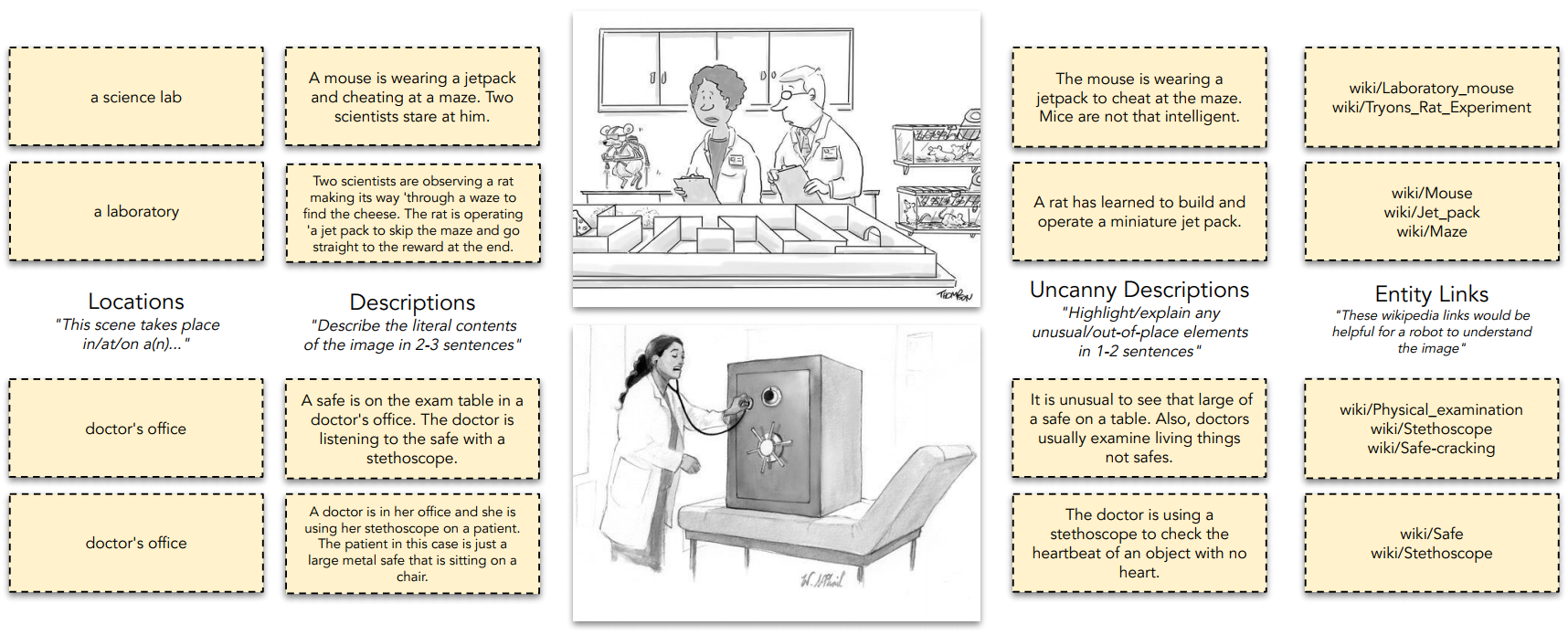
Figure 3: For each of 704 cartoons, we gather several types of annotations from human participants, including locations, descriptions, descriptions of uncanniness, and relevant entities in the form of English Wikipedia links. 704개의 Cartoons에 대해 수집된 Locations, Descriptions about location, Uncanny Descriptions about location, Enitity Links에 관한 주석은 FD Setting의 input data로 활용되거나, FP Setting에서 훈련 시에 사용 가능한 추가 정보로 활용
3. Experiments
기본 설정 : 5 cross-validation splits을 사용하여 전체 데이터가 test에 사용되도록 설정
FP 모델 : 2가지 vision+language model을 사용 (CLIP, OFA Huge 모델 사용)
FD 모델 : 5가지 language model을 사용 (T5-large, T5-11B, GPT-3, GPT-3.5, GPT-4)
3-1. Matching and Quality Ranking Results
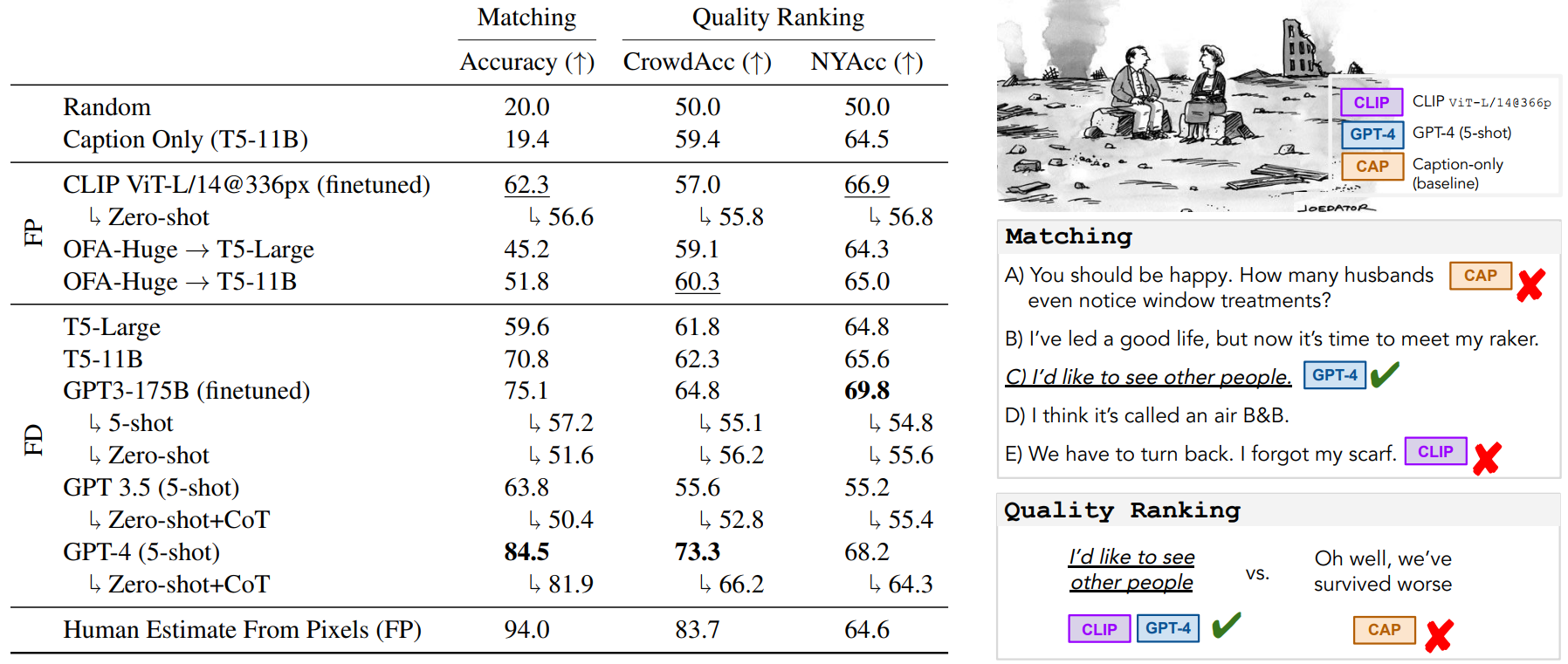
Table 2 : Predictino results for the matching and quality ranking tasks : averages over 6 cross-validation splits. - FD 모델에서는 GPT-4 (5-shot)이 일반적으로 가장 좋은 성능을 보임.
- Matching과 CrowdAcc의 Quality Ranking에서는 모델들의 성능이 Human Estimation보다 일반적으로 낮았으나,
- NYAcc의 Quality Ranking에서는 상대적으로 비등하거나 더욱 더 좋은 성능을 보임
- FP모델에서는 CLIP (finetuned)이 일반으로 양호한 성능을 보였으나, 전반적으로 Human Estimation보다 성능이 낮은 것으로 확인됨.
3-2. Human Evaluation of Explanation
Human Estimation의 경우 투표를 통해 best explanation을 결정하는 방식으로 task를 수행하였으며, 전체 모델들에 대한 Explanation 평가는 7가지의 질문을 바탕으로 평가됨.
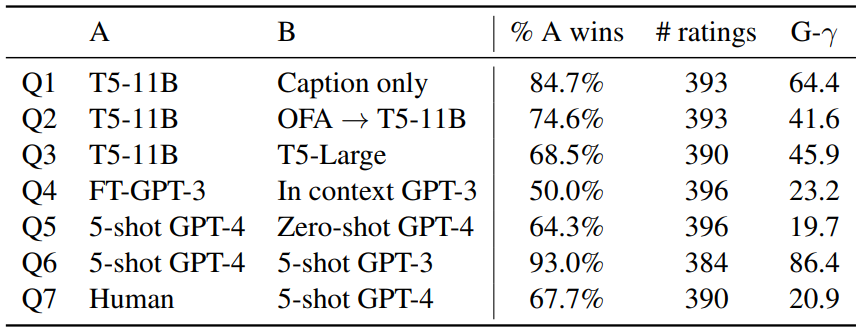
Table 3 : Pairwise human evaluations for explanation, with per-instance agreement. Explanation의 예시는 다음과 같음

Figure 5 : A randon sample of caption explanations generated by a fine-tuned version of GPT-3, GPT-4 with 5 shots. - 인간이 작성한 explanation이 모델이 작성한 explanation보다 선호되며,
- in-context와 fine-tuned 방식이 유사한 성능을 보임.
- vision+languange model의 경우 vision 성능이 bottleneck이 될 수 있음
4. Related Work
Root of Humor : based on Raskin and Attardo
- Hostility : 누군가 혹은 무언가에 대한 우월함을 주장하는 것
- Release of a Constraint
- Incongruity : 일반적으로양립할 수 없는 문맥 혹은 단어
5. Conclusion
여전히 vision+language model은 인간의 수준과 유사하게 caption relevance, evaluate, explain task를 수행하지는 못하지만, 부분적으로는 인간의 수준을 능가하는 지점을 갖고 있다는 점에서 유의미하다.
6. Limitations
- 모델이 가진 유머의 이해도를 New Yorker caption contest라는 특정한 분야로 한정
- 모든 종류의 유머를 포괄하는 연구는 아님
- 설명(explanations in annotated corpus)의 경우 단일 저자에 의해 작성됨 (다양성 문제)
'deep learning > paper review' 카테고리의 다른 글