-
[review] Addressing fairness in artificial intelligence for medical imagingdeep learning/paper review 2024. 3. 24. 18:41
원문 링크 : Addressing fairness in artificial intelligence for medical imaging | Nature Communications

Insight
관련 범용적으로 작동할 수 있는 인공지능이 있을까 하는 의문을 갖게 하는 review라고 생각된다. 의료 부분에서의 범용성을 갖기 위해서는 인종적 다양성, 사회경제적 다양성, 연령의 다양성 등 정말 다양한 다양성이 필요로 하며, 개별 개체의 특징을 토대로 anomal detection을 수행하는 분야라는 점에서, 범용성의 정의가 다르게 정의될 필요가 있다는 것을 깨닫게 되었다. 특히 LLM이 갖고 있는 편향과 그로 말미암은 downstream tasks에서의 발생 가능한 편향을 극복하기 위해 단순한 debiasing 혹은 단순히 database의 다양성을 키우는 방식이 필요한 것이 아니라, 편향의 정의 뿐만 아니라 공정성과 보편성, 이에 기초한 범용성의 정의를 확고히 정의내리는 것이 연구의 방향성을 결정하고 AI의 건강한 파급효과를 만들어내는데 필수적이지 않을까 생각하게 되었다. 가장 인상 깊었던 것은, fairness를 어떻게 정의할 것이며, 그 정의의 세분화를 위해 AI의 사용 대상이 되는 소비자들의 다양성을 가장 먼저 고려해야한다는 사실이었다.
Abstract
의료 영상 분야에서 AI 시스템의 사용이 증가하고 있는 가운데 공정성의 의미와 편향의 잠재적 원인, 그리고 이를 완화하기 위한 전략에 대해 논의
Introducing
최근 Machine learning의 공정성 연구 커뮤니티를 중심으로 ML 시스템이 연령, 인종, 민족, 성별, 사회 경제적 지위 등과 같은 sub-group 간에 상이한 성능을 보여주며, 따라서 특정 인구를 대상으로 편향될 수 있음을 강조하고 있음. health care 영역에서 알고리즘이 갖고 있는 잠재적인 불평등성은 생명 윤리에 반하는 결과를 만들 수 있으며, 따라서 의료 영상 분야에서의 공정성을 키우기 위한 노력과 시도는 굉장히 중요.
What does it mean for an algorithm to be fair?
불균형한 데이터 기반의 MIC 시스템 모델을 사용할 경우, 증상에 대한 진단 정확도가 인종, 피부색 등의 차이에 따라 큰 차이가 발생하는 경우가 있음. 이러한 현상에 대해서는 불공평하다고 쉽게 느끼지만, 반대로 무엇이 과연 공정한 알고리즘인가를 확립하기 위한 기준을 세우는 것은 상당히 어려운 문제. 특히 특정 집단의 유병률이 높은 경우(특정 집단의 성질 및 특성이 유병률과 독립적이지 않은 경우)에 있어서는 일률적으로 적용될 수 있는 공정한 알고리즘 혹은 공정성의 정의가 존재하지 않을 것.

xmrgl wlFigure 1 : Group-fairness metrics. As a consequence of the difference in disease frequency, the model would not fulfill the demographic pariy criterion. Three reasons behind biased systems : data, models and people
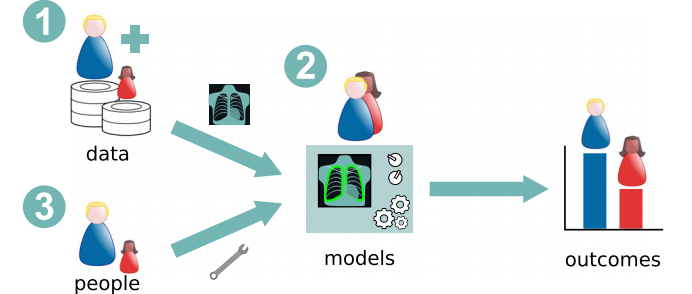
Figure 2 : Main potential sources of bias in AI systems for MIC. Data : Train database에 인구 다양성과 대표성이 부족한 경우 (인구통계학적 구성과 대상 인구가 일치하지 않은 경우) 편향된 시스템이 만들어질 수 있음. (symptom image와 함께 이에 대한 소견과 관련된 라벨이 전달될 때 인구통계학적 특성이 반영되지 않아 편향이 발생하기도 함)
Models : 모델의 architecture, hyperparameter, loss function 등에 의해 편향의 증폭 및 완화에 있어 기능.
People : ML 시스템이 특정한 공정성의 정의를 위반하였다는 이유로 편향된 시스템으로 간주해서는 안되며, 특정 사용 사례에 따라 공정성을 평가하고 보장하기 위한 적절한 metric을 선정하고 사용하기 위한 인간의 섬세한 작업이 필요. 이 과정에서 특정 background를 공유하는 group의 독점적 결정에 의한 자연발생적인 편향이 발생할 수 있음.
Structural : 환자별 증상의 징후의 차이, 경제적 차이로 인한 치료 지연, 저소득 국가에서의 연구 부족 등 사회 경제적 원인으로 인한 연구 실적 및 결과물의 부재로 인한 편향이 발생될 수 있음.
Bias mitigation strategies
기본적으로 모델 알고리즘의 공정성을 높이는 작업은 서로 다른 결과물을 낳을 수 있지만, 가장 중요한 것은 알고리즘의 편향을 고려하는 데 있어 다양한 측면과 속성, 특성을 갖고 있는 다양한 집단이 중심이 되어 다양한 가치를 논하며 알고리즘을 구성하고 편향을 극복하려는 시도를 해야한다는 것/
Before Training
- representative data를 더욱 더 수집하여 균형을 맞추는 방법 : 환자로부터 데이터 사용을 위한 동의를 받는 것도 쉽지 않으며, 특정 조건에서 유병률이 낮은 경우 관련 데이터를 얻는 것도 충분하지 않음. 이에 대한 대안으로 민감 정보를 삭제하고 데이터를 사용한다거나, 데이더 resampling 기법을 많이 사용
During Training
- Adversarial training과 data augmentation 기법을 사용
After Training
- 서로 다른 sub-group에 걸쳐 prediction을 수행하여 결과를 비교하는 것이 필요
Challenges and outlook for fairness studies in MIC
하지만 공정성 제고를 위한 추가적인 노력들이 많이 필요한 실정인데, 상당히 많은 도전적인 tasks들이 존재한다.
Areas of vacancy
공정성 보장을 위한 알고리즘 분석의 대상이 되는 학문적 범위가 여전히 협소하다. 이러한 현상은 주로 개인 유출과 관련하여 정보를 제공하지 않아 데이터베이스의 부족으로 인해 발생하는 경향이 크다. 이를 해결하기 위해서는 개인정보를 보호하고 침해하지 않는 수준에서 환자의 동의를 얻어 데이터베이스 자료 등을 구축하는 것이 필요하지만, 무엇보다도 어떤 속성을 활용하여 데이터베이스를 구축하는 것이 효과적인지에 대한 통찰이 우선적으로 필요하다.
- radiology, dermatology, ophtthalmology, cardiology 이 네 분야를 중심으로만 연구가 이루어지고 있다.
Incorporating fairness audits as common practice in MIC studeis.
MIC 연구에 있어 공정성 보장과 관련한 주요한 단일의 컨퍼런스가 부재하며, 그 결과 연구도 파편적으로 수행되어 발표됨에 따라, 해당 분야의 중요성 및 전문성이 결여되는 문제가 있다는 점에서, 공동체 내에서 집약적이고 집중적인 논의의 장이 필요하다.
Increasing diversity in database construction
Database 수준에서의 편향을 줄이기 위해 다양한 속성과 특징을 가진 사람들의 database가 필요하며, 특히 저소득 국가의 데이터를 수집할 수 있는 역량과 도전이 필요하다.
Rethinking fairness in the context of medical image analysis.
다른 영역과는 차별적으로, medical image 영역, 나아가 medical 영역에서의 AI 사용에 있어 공정성의 정의는 굉장히 중요한 문제이다. 해부학적 특성 등과 같은 자연 발생적인 요소로 인한 차이로 인해 AI를 활용한 anomal detection에 있어 편향적인 성능 차이를 유발할 수 있기 때문이다. 모델의 loss를 줄이는 과정에서 majority를 대상으로 하는 성능이 낮아질 수 있다는 문제도 있고, 이는 생명윤리에 굉장히 반하는 문제이기도 하다. 나아가 어떤 집단을 minority group 혹은 majority group으로 간주할 것인가를 결정하는 것 역시 중요한 문제가 된다. 그 이유로 model의 metric도 model의 성능과 관련하여 편향과 불평등을 만들 수 있는 것이다.
<추가적으로 찾아볼 문헌>
FUTURE-AI: Guiding Principles and Consensus Recommendations for Trustworthy Artificial Intelligence in Medical Imaging
'deep learning > paper review' 카테고리의 다른 글