-
[review] TRAC : Trustworthy Retrieval Augmented Chatbotdeep learning/paper review 2024. 3. 25. 21:46
원문 링크 : [2307.04642] TRAC: Trustworthy Retrieval Augmented Chatbot (arxiv.org)
TRAC: Trustworthy Retrieval Augmented Chatbot
Although conversational AIs have demonstrated fantastic performance, they often generate incorrect information, or hallucinations. Retrieval augmented generation has emerged as a promising solution to reduce these hallucinations. However, these techniques
arxiv.org

* Summary
RAG 모델은 LLM이 유발하는 Hallucination 문제를 어느 정도 극복하였으나, 답변 내용의 정확도 측면에서는 보장하지 못하는 문제가 있다. 정확도를 통계적으로 보장하기 위해 ‘Conformal Prediction’과 이를 평가하기 위해 ‘Global Testing’을 결합하였고, Global Testing 과정에서 모델의 최적의 답변 set의 크기를 결정하기 위해 Bayesian Optimization을 수행하여 모델의 효율성을 극대화 함.
Conformal Prediction을 RAG에 적용하기 위해서는 Retrieval model과 Answering model에 개별적인 Predictor를 제공해야한다. Retrieval model에서는 특정 질문에 대한 관련된 정보를 모두 검색하고, 특정 임계값 이하의 비이상 측정점을 갖는 context만을 보관 (신뢰도 기반의 측정점)하며, Answering model에서는 Retrieval model에서 보관 context 중 가장 관련성이 있는 context와 관련한 answering을 생성하여 특정 임계값 이하의 비이상 측정점을 갖는 context만을 보관한다. (신뢰도 기반의 측정점)
이 때 각 model에서의 비이상 측정점은 서로 다르게 구성되며, 이러한 측정점은 사용한 context를 신뢰할 수 있는지 여부를 점수로 표기하고 hyperparameter로 통제할 수 있다는 점에서 통계적 보장을 하고 있다고 판단할 수 있다.
이러한 RAG 모델의 신뢰도를 평가하기 위해 Global test 중 Boferroni Correction과 Harmoic Mean p-value 방법을 사용하며, Bayesian Optimization을 통해 최적의 신뢰값을 찾는다.Abstract
RAG는 LLMs의 hallucination 현상을 해결하는 데 유용하지만, 정확도를 보장하지는 않는다는 점에서, 본 논문은 conformal prediction과 global testing을 활용한 RAG QnA 시스템을 위한 통계적 보장을 제공하는 framework를 제안. 더불어 global testing에 bayesian optimzation 기법을 사용하여 성능 향상.
Introduction
본 논문에서는 믿을 수 있는 RAG 기반의 QNA시스템을 보장할 수 있는 framework를 제공.
LLM의 hallucination을 극복하기 위한 대안으로 RAG가 활용.
RAG기반의 QA 시스템에 conformal prediction을 사용하는데 발생가능한 문제점
- conformal prediction은 QNA보다 단순한 classification과 regression task에 적용
- RAG는 많은 요소로 구성되어 있다는 점에서 각 구성요소를 대상으로 개별 작업이 필요
- need to devise reasonable metrics for quantifying the set size for question answering.
Framework
- construct individual conformal predictors : retrieval model과 question answering model
- combine techniques by using global test - bayesian optimization을 활용하여 global test의 최적화 진행
- prompt가 주어지면 retriever는 높은 확률로 가장 관련있는 맥락을 포함하는 set of contexts를 검색 후 반
Related Work
Retrieval Augmentation
- knowledge base를 활용하여 question에 대한 정보를 검색 후 답변하는 형식으로 hallucination을 효과적으로 줄임
- 외부 database를 활용하지 않고 다른 LLM으로부터 context를 검색하는 parametric memory 방식도 효과적
Conformal Prediction (CP)
- 불확실성 정량화 기술 (모델의 예측에 대한 신뢰도를 정량적으로 평가하고 성능 보증을 제공하는 기법)
- 모델이 예측한 결과가 실제 값과 일치할 확률을 고려하여 신뢰 구간 또는 신뢰 영역을 생성
- 주어진 모델에 대한 대답의 집합을 구하되 그 집합이 정답을 높은 확률로 포함하게 구성하는 것이 목적으로,
- 모든 예측에 대해 정해진 신뢰 수준에서 true label이 예측 세트 안에 포함될 것을 보장하는 것
- 계산이 복잡하다는 단점을 극복하기 위해 Split conformal prediction(SCP)를 사용하기도 함
<conformal prediction>
신뢰도 있는 예측을 제공하기 위한 통계적 방법론으로, 예측의 불확실성을 추정하고 예측의 신뢰도를 제공하기 위해 사용하는 방법론
- 모델 훈련
- 신뢰 구간 생성 : 훈련된 모델을 사용하여 새로운 data가 입력되었을 때 해당 data가 속할 것으로 예상되는 클래스를 예측하여 신뢰 구간을 생성 (예측의 불확실성을 고려하여 특정 범위 내에서 예측이 수행 / 특정 범위에 속할 경우 특정 class에 소속되는 형식)
- 외부 데이터로 평가 : 훈련 데이터와는 외부 데이터를 사용하여 모델을 평가한 뒤, 모델의 각 예측에 대한 신뢰도를 확인하고 조정
- 보정 (calibration) : 예측의 신뢰도가 부족한 경우 보정을 통해 신뢰할 수 있는 예측 생성
<Split comformal prediction>
전통적인 conformal prediction을 사용하지만, computational efficiency 향상을 위해 데이터 분할 기법을 사용
- 데이터 분할
- 전통적인 conformal prediction : 모든 input에 대해서 score를 계산하여 예측의 신뢰도 점수를 사용하여 신뢰 구간을 생성
- SCP의 경우 train set과 calibrate set으로 구분하여, 모델은 train set을 통해 학습되며, 신뢰도 점수는 학습된 모델이 calibrate set를 통해 예측한 결과값과 실제 레이블 값 간의 차이를 고려하여 계산 (신뢰도 점수는 calibrate set를 통해서만 계산되고 갱신)
- 추정된 신뢰도를 기반으로 각 예측에 대한 신뢰도 구간을 형성하고,
- 형성된 예측 신뢰도 구간을 사용하여 모델 전체의 예측 신뢰도를 평가하고 보정
: SCP를 사용한 결과, 새로운 데이터가 입력되었을 때, 새로 입력된 데이터와 예측 세트 내에 있는 예측 값과의 차이 (score : nonconformity measure)가 사용자가 지정한 값(NCM score)보다 작거나 같은 경우에 한에서 새로운 데이터에 대한 예측값으로 지정됨 (즉 새로 입력된 데이터가 훈련 데이터를 통해 예측된 결과값들과의 차이 값이 사용자가 지정한 hyperparameter 값보다 작거나 같을 경우에는 해당 결과값이 새로 입력된 데이터의 예측값이 될 수 있음을 의미)Global testing
global hyphothesis test : 여러 개별 가설들의 집합인 글로벌 귀무 가설을 테스트하는 다중 가설 검정 기법으로, 다양한 component로 구성된 시스템에서 개별 component들에 대한 평가를 바탕으로 전체 시스템에 대한 통계적 보장을 제공. <구체적인 평가 방법에 해당>
- Boferroni Correction : 개별 테스트의 유의 수준을 조정하여 전체 가설들을 동시에 테스트 하는 방법으로, 가장 단순하고 보수적인 접근 방식 중 하나
- Fisher’s Test : 여러 개의 p값을 결합하여 하나의 통계적으로 유의미한 테스트 결과를 도출하는 방법
- Harmonic Mean p-value : 여러 개의 독립적인 테스트 결과를 조화 평균하여 하나의 p값을 계산하는 방법Methods
Individual Prediction Sets
예측 가능한 결과값의 세트 C는 random으로 선택되는 calibration set B에 의해 영향을 받는다.
RAG 기반의 QA 시스템에 conformal prediction을 적용하기 위해서는 각 components에 적합한 nonconformity measure(NCM)를 디자인하여 적용해야한다. NCM은 주어진 질문 x에 대한 true label인 y (given label)와의 차이를 측정하는 함수이다. (앞서 언급한 challenging point) <nonconformity measure(NCM)는 손실함수라고 생각하면 직관적인 이해에 도움이 된다>
- retrieval model : prompt와 context embedding 간의 negative 내적 또는 negative cosine similarity를 사용(거리 개념을 활용)
- question answering model
- 로그 함수를 사용한 NCM은 유사한 의미를 가진 답변에 대해서도 로그 확률의 차이를 유발할 수 있다는 한계를 가진다는 점에서, 본 논문의 알고리즘은 Monte Carlo Sampling and Clustering을 통해 평가할 수 있는 negative semantic confidence를 NCM으로 사용
- K개의 답변에 대해 entailment model이나 NCM score를 활용하여 의미적으로 clustering을 하고, 각 cluster를 기준으로 평가
* entailment model : 문장 간의 의미적 관련성을 평가하고 문장 간의 관계를 분류하는 데 사용되는 모델 (최근의 자연어 처리 모델들은 entailment model의 기능을 포함하고 있어, 문장 간의 의미적 관련성을 파악하고 다양한 자연어 이해 작업 수행)
‘ground truth’ label 의 정의
- retrieval model : most relevant context
- question answering model : 각 질문에 해당하는 상위 1개의 가장 관련성이 높은 context가 주어지고, 이 context와 retrieval model에서 결정된 context 간의 Roughe F1 score와 threshold 값을 활용하여 두 context 간의 의미적 동등성을 비교하여 실제 정답 label로 간주
<짚고 넘어갈 점>
Retrieval 단계에서, Cret(x)에는 특정 임계값 이하의 비이상 측정점를 갖는 모든 context가 존재하며, 그 중에서 관련성이 가장 높은 (가장 작은 비이상 측정점을 갖는) context가 ground truth로서 true label c∗가 된다.
Quenstion Answering 단계에서, CQA(x)에는 주어진 질문 x와 가장 관련성 높은 c^를 바탕으로 예측 세트를 구성하며, 질의응답 모델이 생성한 특정 임계값 이하의 비이상 측정점을 갖는 모든 가능한 답변 y가 포함된다. 그 중에서 CQA(x)의 ground truth로서 true label은 생성한 답변과 c^와의 Rouge F1 score를 통해 답변 간 의미적 동등성이 가장 좋은 답변을 ground truth로 설정Prediction sets의 경우 collected questions를 calibration과 testing sets로 동등한 크기로 분할한다.
모델의 훈련 과정은 크게 두 단계를 거친다. 검색 단계와 답변 생성 단계를 거친다.
- 검색 단계 : 주어진 question에 적합한 context를 검색하며, 특정 임계값 이하의 비이상 측정점을 갖는 모든 context가 Cret(x)에 포함
- 답변 생성 단계 : 주어진 question과 c∗를 바탕으로 답변을 생성하며, 생성된 모든 답변은 CQA(x)에 포함
End-to-End Prediction Sets
주어진 질문 x에 대한 최종 예측 세트는, 검색 단계에서 선택된 context들에 대해 QA 모델이 만들어낸 가능한 모든 답변들의 합집합
- 이를 통해 시스템은 질문 x에 대해 하나 이상의 답변을 제공할 수 있다. 이를 통해 다양한 관련 정보를 종합적으로 고려할 수 있고 포괄적인 답변을 제공할 수 있다.
Global tests 수행 : 각각의 component를 평가하는 데 있어 개별 conformal predictors를 사용하며, 크게 두 가지 방법에 초점을 두고 global test 수행
- Bonferroni Correction(Bonf)
- Harmonic Mean p-values(HMP)
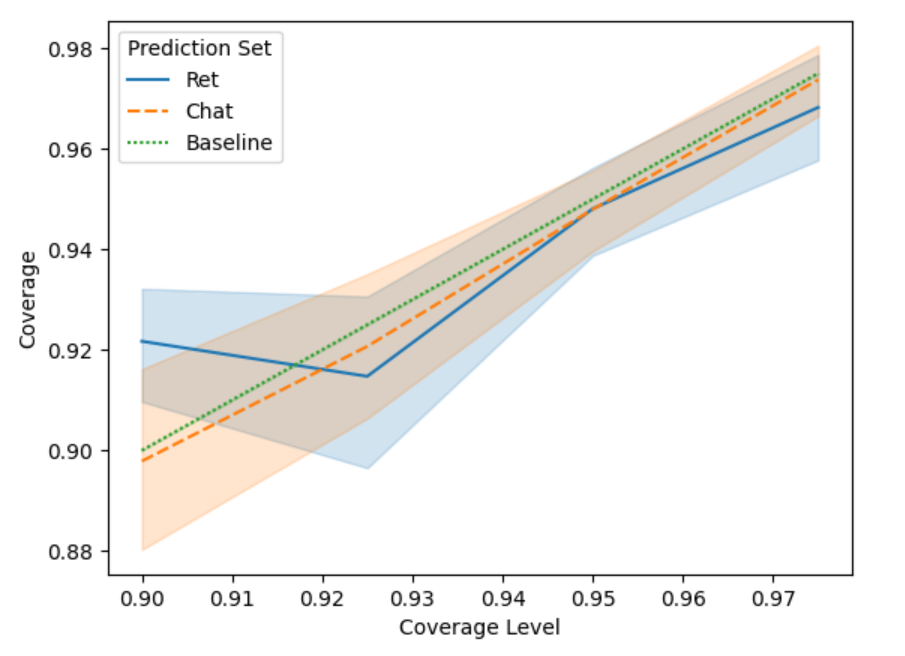
Figure 1 : Empirical Coverage Rates with Different Levels Hyperparameter Optimization
- Bonf : αret
- HMP : αQA
예측의 정확도에는 영향을 미치지 않지만 예측 set의 크기를 결정하는 parameter로, Bayesian optimization을 활용하여 최적의 hyperparameter를 선택하며, 이를 CCPS라고 명명 (Combining Conformal Prediction Sets via Optimized Multiple Hypothesis Testing)
'deep learning > paper review' 카테고리의 다른 글
